Self-Hosting a Codebase Intelligence Platform with Docker
As engineering teams scale, the primary bottleneck isn't usually writing code—it's understanding it. Between technical debt, architectural drift, and the "bus factor" inherent in specialized modules, the cognitive load required to contribute to a modern codebase is staggering. While AI coding assistants have promised to bridge this gap, they often struggle with the lack of deep, structural context. This is where a self-hosted code wiki and intelligence platform becomes an essential part of the modern developer experience.
In this guide, we will explore how to self host documentation and codebase intelligence using repowise, an open-source platform designed to provide a "second brain" for your engineering team. By the end of this post, you'll have a production-ready instance of repowise running in Docker, providing your team with auto-generated wikis, git intelligence, and a Model Context Protocol (MCP) server for your AI agents.
Why Self-Host Your Code Intelligence?
The decision to self-host a codebase intelligence platform isn't just about cost; it’s about the fundamental security and utility of your most valuable asset: your source code.
Privacy: Your Code Never Leaves Your Infra
For many organizations, the idea of uploading an entire proprietary codebase to a third-party SaaS for indexing is a non-starter. When you self host documentation tools like repowise, the indexing, vectorization, and analysis happen within your own VPC or local hardware. You maintain complete control over where your data resides.
Compliance Requirements
Industries like fintech, healthcare, and defense operate under strict regulatory frameworks (SOC2, HIPAA, GDPR). These frameworks often mandate that code-level metadata and documentation remain on-premises or within approved cloud boundaries. A private code documentation strategy ensures you meet these audit requirements without sacrificing the benefits of AI-driven insights.
Customization and Control
Self-hosting allows you to tailor the resource allocation to your needs. Whether you need to index a massive monorepo using high-memory instances or prefer to run a lightweight instance for a small set of microservices, Docker-based deployments give you the flexibility to tune the environment variables and storage backends.
No Vendor Lock-In
repowise is licensed under AGPL-3.0, ensuring that the platform remains open and accessible. By hosting it yourself, you aren't at the mercy of a SaaS provider's pricing changes or service deprecations. You own the infrastructure, the index, and the generated insights.
 Repowise System Architecture
Repowise System Architecture
Architecture of a Self-Hosted repowise Instance
To effectively run a self hosted code intelligence platform, it’s important to understand the components working under the hood. repowise isn't just a static site generator; it’s a dynamic intelligence layer.
SQLite for Metadata + Wiki
While many platforms reach for heavy relational databases like PostgreSQL, repowise utilizes SQLite for its metadata and wiki storage. This choice simplifies self-hosting by removing the need for a separate database container, while providing more than enough performance for even the largest codebases. It stores the structure of your wiki, the freshness scores of your documentation, and the results of the git intelligence ownership maps.
LanceDB for Vector Search
For semantic search—the ability to ask "How do we handle user authentication?" and get relevant code snippets—repowise uses LanceDB. LanceDB is an embedded, serverless vector database that is exceptionally fast for high-dimensional data. It allows repowise to perform RAG (Retrieval-Augmented Generation) locally without the overhead of a managed vector service.
MCP Server for AI Agent Access
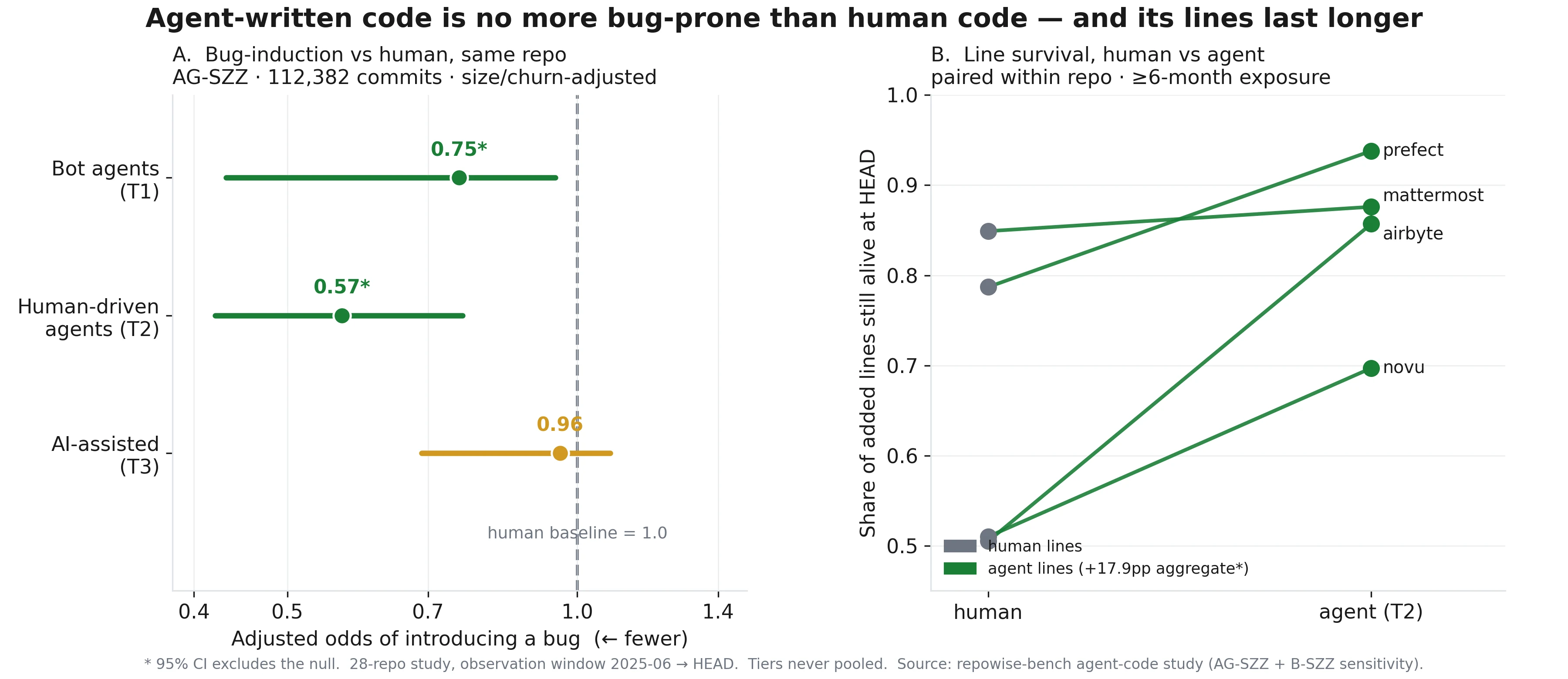
One of the unique features of repowise is its built-in Model Context Protocol (MCP) server. This exposes 9 structured tools that allow AI agents (like Claude Code or Cursor) to "read" your documentation and understand your architecture. You can see all 9 MCP tools in action to understand how they transform raw code into actionable context for LLMs.
Web UI for Browsing
Finally, the Web UI provides a human-readable interface. It visualizes the dependency graph, shows hotspot analysis (where churn meets complexity), and allows developers to browse the LLM-generated wiki for every file and module in the system.
Deployment Options
Before we dive into the Docker setup, let's look at the three primary ways to deploy repowise:
| Method | Best For | Pros | Cons |
|---|---|---|---|
| pip install | Individual developers | Fastest setup, minimal overhead | Manual dependency management |
| Docker Compose | Small to medium teams | Consistent environment, easy updates | Requires Docker knowledge |
| Kubernetes | Enterprise/Scale | High availability, auto-scaling | High configuration complexity |
For most organizations looking for a docker code docs solution, Docker Compose is the "Goldilocks" choice—providing the right balance of ease and reliability.
Step-by-Step: Docker Compose Setup
Setting up a self hosted code wiki with Docker ensures that your environment is identical to the development environment, reducing "it works on my machine" issues.
Prerequisites
- Docker and Docker Compose installed.
- An API key from an LLM provider (OpenAI, Anthropic, or Google Gemini) OR a local Ollama instance running.
- At least 4GB of RAM allocated to Docker.
The docker-compose.yml
Create a new directory for your repowise instance and add the following docker-compose.yml file:
services:
repowise:
image: ghcr.io/repowise-dev/repowise:latest
container_name: repowise
volumes:
- ./data:/app/data
- /path/to/your/codebases:/codebases:ro
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY}
- REPOWISE_DATA_DIR=/app/data
- REPOWISE_PORT=8080
ports:
- "8080:8080"
restart: unless-stopped
Environment Configuration
Create a .env file in the same directory:
OPENAI_API_KEY=your_sk_...
# Optional: If using local Ollama
# LLM_PROVIDER=ollama
# OLLAMA_BASE_URL=http://host.docker.internal:11434
LLM Provider Setup
repowise is provider-agnostic. While OpenAI offers the highest quality documentation generation, you can run a fully air-gapped setup using Ollama with models like Llama 3 or Mistral. This is the ultimate setup for private code documentation.
Running the Stack
Launch the container:
docker-compose up -d
Check the logs to ensure the server started correctly:
docker-compose logs -f repowise
Indexing Your First Repository
Once the container is running, you need to tell repowise which codebases to analyze. You can learn more about how this works on our architecture page.
Running repowise init Inside Docker
You can execute commands inside the running container to initialize a new repository.
docker exec -it repowise repowise init /codebases/my-project
This command scans the directory, identifies the tech stack, and creates a configuration file. Next, trigger the indexing process:
docker exec -it repowise repowise index /codebases/my-project
During this phase, repowise will:
- Parse imports to build a dependency graph.
- Mine git history for hotspot analysis.
- Generate LLM documentation for every file and symbol.
- Create vector embeddings for semantic search.
 The Indexing Pipeline
The Indexing Pipeline
Setting Up the Web UI
With the repository indexed, it's time to explore the intelligence repowise has gathered.
repowise serve
The Docker image automatically runs the repowise serve command. This starts the Next.js-based Web UI and the MCP server on the specified port (default 8080).
Accessing the Dashboard
Navigate to http://localhost:8080 in your browser. You will be greeted with a dashboard showing:
- Architecture Summary: An LLM-generated overview of how the project is structured.
- Health Metrics: Documentation freshness scores and "Bus Factor" warnings.
- Interactive Graph: A navigable map of your module dependencies.
- Search: A semantic search bar to query your codebase in natural language.
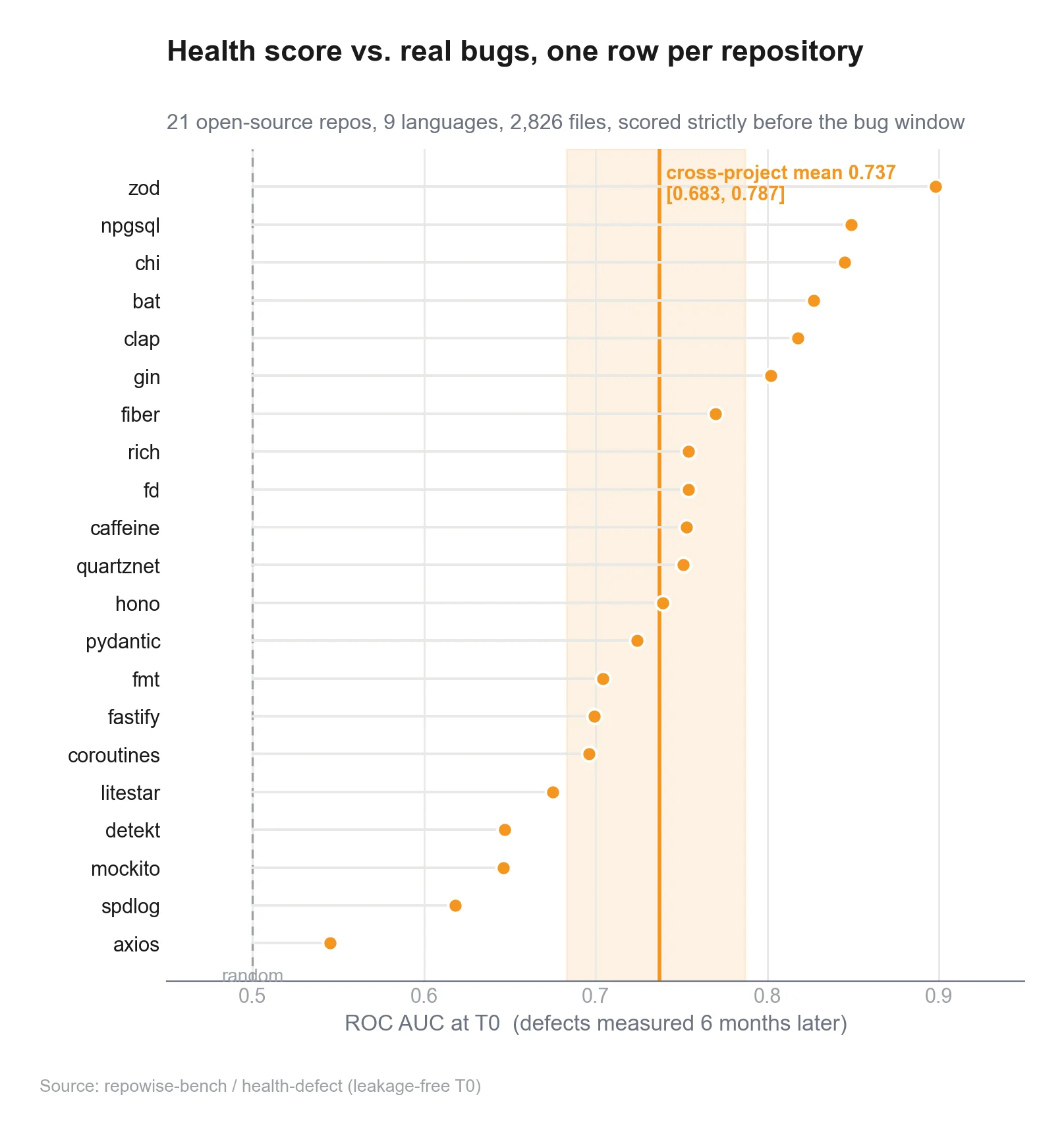
You can see what this looks like in practice by exploring our live examples, which showcase the UI populated with real-world repository data.
Production Considerations
When moving from a local test to a team-wide self hosted code intelligence platform, keep these factors in mind:
Persistent Storage
In our Docker Compose example, we mapped ./data to /app/data. This is crucial. This directory contains your SQLite database and LanceDB index. If you lose this volume, you lose all generated documentation and will need to re-index (and re-pay for LLM tokens).
Backup Strategy
Since repowise uses SQLite, backups are straightforward. You can use the sqlite3 CLI to perform a "hot backup" or simply snapshot the volume while the container is briefly stopped.
Update Workflow
To update repowise, pull the latest image and restart:
docker-compose pull
docker-compose up -d
Repowise handles database migrations automatically on startup.
Resource Requirements
For large repositories (>500k LOC), indexing can be memory-intensive. Ensure your Docker host has sufficient swap space and at least 8GB of RAM if you are running community detection algorithms on complex dependency graphs.
 MCP Tool Registry
MCP Tool Registry
Key Takeaways
Self-hosting your codebase intelligence with repowise and Docker provides a powerful, secure, and extensible way to manage technical debt and accelerate developer onboarding.
- Privacy First: By using Docker, your code and its metadata remain under your control.
- AI-Ready: The built-in MCP server turns your documentation into a structured API for the next generation of AI coding agents.
- Deep Insights: Move beyond basic search with git intelligence, dependency analysis, and automated wiki generation.
- Operational Simplicity: A single Docker container manages the UI, the indexer, and the intelligence engine.
Ready to transform how your team understands code? Start by exploring the auto-generated docs for FastAPI to see what repowise can do for your codebase today.
Frequently Asked Questions
Q: Can I run repowise without an internet connection? A: Yes. By configuring repowise to use a local Ollama instance and local embedding models, you can run the entire stack in a completely air-gapped environment.
Q: How long does indexing take? A: For a medium-sized repo (e.g., Starlette), initial indexing takes 2-5 minutes. Subsequent updates are faster as repowise only re-indexes changed files.
Q: Does it support my language? A: repowise currently supports 10+ languages including Python, TypeScript, Go, Rust, Java, and C++. It uses Tree-sitter for high-fidelity parsing across all supported stacks.