Building a Deterministic PR Review Bot With Zero LLM Calls
Building a Deterministic PR Review Bot With Zero LLM Calls
A deterministic PR review bot can do useful review work without calling an LLM once. That sounds odd until you break “review” into smaller jobs: parse the changed files, map the dependency paths, score the touch points, and emit one comment that stays stable across runs. This post shows the architecture we use for a deterministic pr review bot, why we prefer it over a no llm code review agent that guesses, and how a github bot architecture based on static analysis gives you a useful code health pr bot with predictable output. Repowise is one implementation of this pattern, but the design applies to any open source pr bot you want to ship. The key constraint is simple: every verdict must come from code, git history, or a graph. No model calls. No drift.
Part of the Change Risk guide.
Why we built a deterministic PR review bot without LLMs
The first reason is repeatability. If the same pull request runs twice, the bot should say the same thing twice. That matters more than it sounds. A PR bot becomes part of your review process, which means people will start making merge decisions based on it. If it changes tone, invents a new concern, or forgets a prior warning, trust drops fast.
The second reason is cost control. A bot that reviews every PR at scale can generate a lot of tokens. A static pipeline does not do that. It runs tree parsing, graph queries, and a few ranking passes. The output is deterministic text assembled from templates, not generated prose.
The third reason is auditability. GitHub’s Checks API is built for machine feedback on commits and pull requests, and it exposes a clear path for creating and updating check runs in a repository. That makes it a good fit for a bot that wants to post structured, fixed feedback instead of free-form chat. (docs.github.com)
There is also a licensing angle. If you want the bot to live in a self-hosted environment, AGPL-3.0 gives you a clean story for server-side software that remains free for its users. The GNU AGPL is specifically written for network server software, which is why it shows up often in open source infrastructure projects. (gnu.org)
 Deterministic PR Flow
Deterministic PR Flow
If you want a concrete place to anchor the rest of this post, start with the pieces repowise already exposes: the architecture page explains the system boundary, and the live examples show what the outputs look like on real repositories.
The architecture
The bot is a pipeline, not a prompt. That is the core design choice.
- Receive a GitHub webhook for a pull request.
- Fetch the diff and changed file list.
- Parse the touched files into symbols and imports.
- Build or reuse a dependency graph.
- Pull git history for ownership, churn, and co-change signals.
- Compute a fixed health score.
- Render deterministic suggestions.
- Post or update one PR comment and one check run.
Tree-sitter fits the parsing step because it gives you concrete syntax trees across many languages, and its CLI is designed to parse source files and report parse errors predictably. (tree-sitter.github.io) NetworkX fits the graph step because it is built around graph objects, directed graphs, and graph algorithms over nodes and edges with attached data. (networkx.org)
The important part is not the libraries themselves. It is the interface between them. Parsing gives you symbols. Symbols become nodes. Imports and references become edges. Git history adds weights. The scorer consumes those weighted nodes and produces a bounded result. Every stage is inspectable.
Tree-sitter for parsing
Tree-sitter solves a practical problem: you need language-aware structure without waiting on an IDE or a language server. For a PR bot, that means you can extract file-level and symbol-level context from the exact diff you are reviewing. Tree-sitter’s parser model is a better fit than regexes because you can point it at a file and get syntax nodes with enough structure to distinguish a function body from a class declaration. (tree-sitter.github.io)
In practice, we use Tree-sitter for three jobs:
- file kind detection
- symbol extraction
- changed-span mapping
The changed-span mapping matters. If a PR touches one function inside a large file, the bot should not treat the whole file as equally risky. It should attach the score to the symbol that actually changed.
NetworkX for graphs
Once you have symbols and imports, the graph is straightforward. Each file or symbol is a node. Each import or reference is a directed edge. NetworkX supports directed graphs and edge attributes, so you can store weights like import strength, edge count, or last-touch timestamp. (networkx.org)
This gives you a few useful queries:
- what depends on this module?
- what does this file pull in?
- which nodes sit on many shortest paths?
- where are cycles concentrated?
- which nodes sit inside high-churn communities?
That last one is where the review bot starts to earn its keep. A file with many dependents, many co-changes, and high churn is a bad place to land a risky edit. The bot does not need to say “this feels dangerous.” It can say “this file has 18 direct dependents, appears in 11 co-change pairs, and sits in the top decile of churn x complexity.”
Git history for churn and coupling
Git history is the cheapest source of engineering truth you have. It tells you which files move together, who touches them, and how often they change. A review bot can mine that for ownership maps, hotspot analysis, and bus-factor signals without reading a single token from an LLM.
This matters because code review is not just about local correctness. It is about blast radius. If a PR touches a hotspot, a coupling-heavy module, or a file with sparse ownership, the bot should surface that context immediately.
Repowise’s hotspot analysis demo is a good way to visualize the churn part of that story, and the ownership map for Starlette shows how git intelligence changes the conversation in review.
12-marker scorer
The scorer is the part that turns raw signals into a review decision. We use a fixed set of markers so the output stays deterministic. The exact set can vary by repo, but the model should stay the same: each signal is measured, normalized, and combined with explicit weights.
A practical 12-marker set looks like this:
- changed symbol count
- lines added
- lines removed
- cyclomatic complexity delta
- file churn
- historical bug density proxy
- dependent count
- fan-in / fan-out
- co-change frequency
- ownership breadth
- test coverage adjacency
- dead-code exposure
The scorer should not be clever. It should be boring. If a file misses tests and sits in the middle of a high-dependency chain, the output should say that every time. If the score clears the threshold, the bot can stay silent. Silence is a feature.
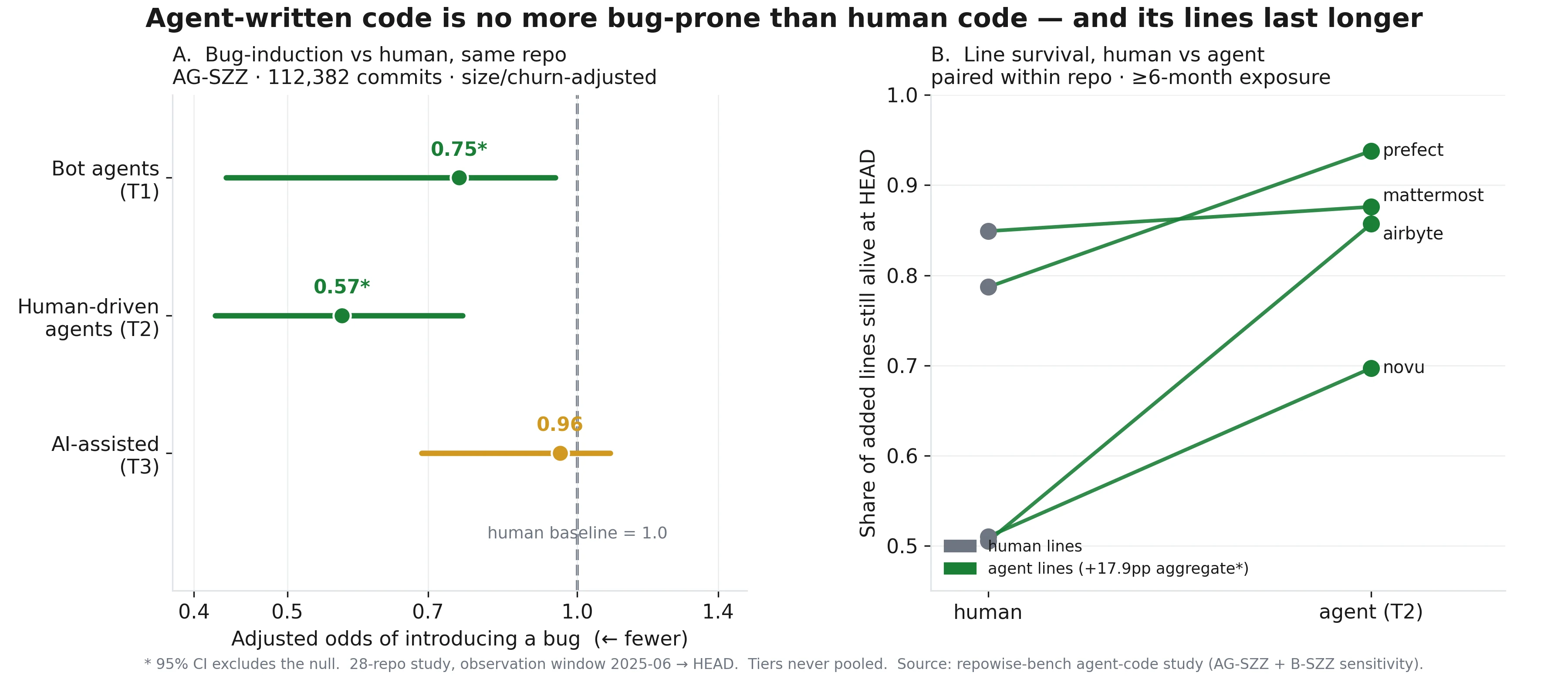
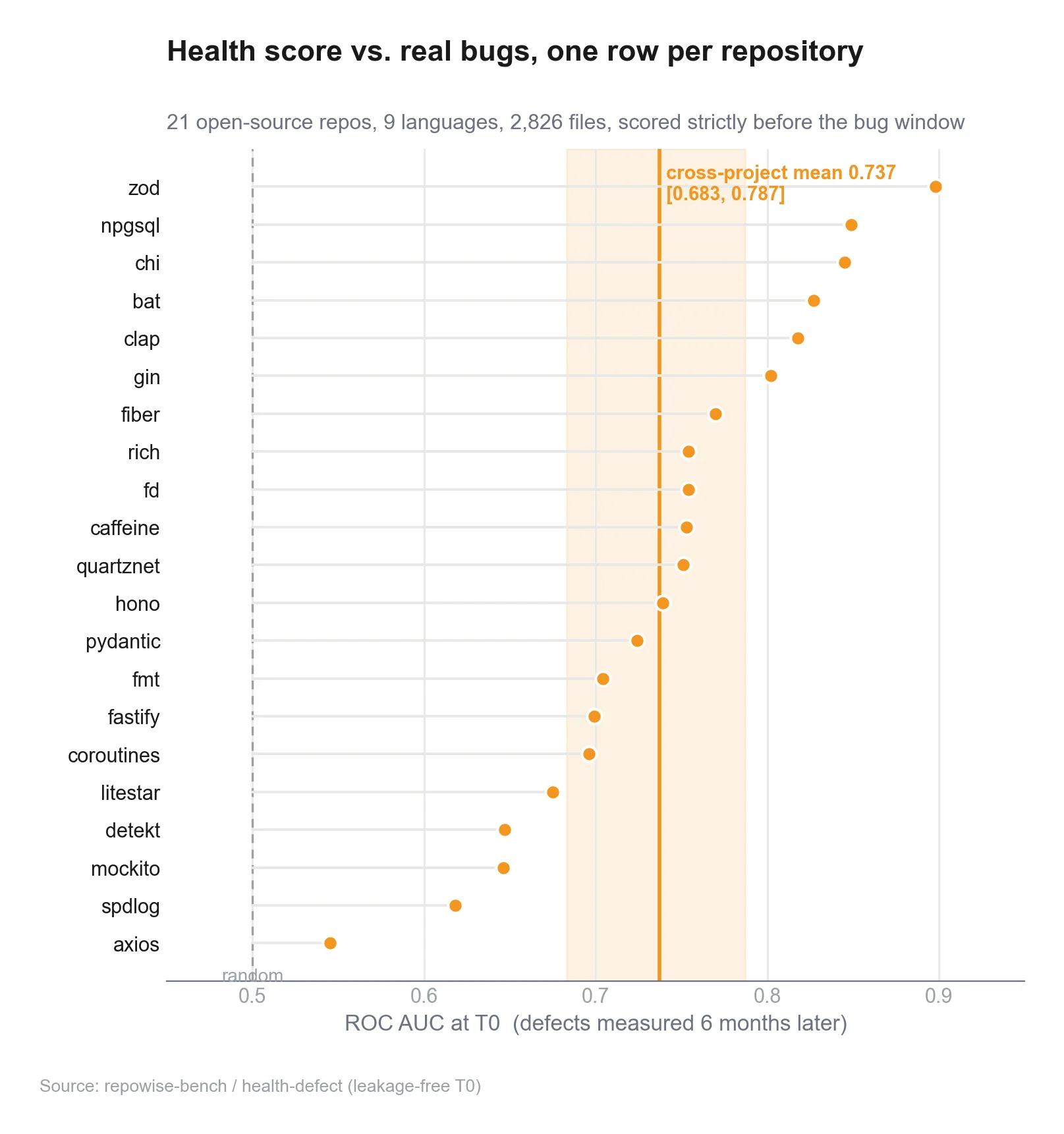
Repowise added a fifth intelligence layer in v0.10.0 for code health, including per-file health scores, module rollups, untested-hotspot detection, refactoring targets ranked by impact-per-effort, and declining-health trend alerts. That is exactly the sort of fixed-feature scorecard that works in a no llm code review flow because it can be computed, logged, and explained. (gnu.org)
Template-string suggestions
The final output should be assembled from templates, not generated text. That does two things.
First, it keeps the comment terse. Review comments get ignored when they ramble. A good deterministic bot uses short sentences with concrete evidence.
Second, it makes the output testable. If a file with no tests and high churn lands in a hotspot, the test should assert that the rendered suggestion contains those facts.
A simple template can handle most cases:
- Risk summary: one sentence
- Evidence: up to three bullets
- Suggestion: one action
- Escalation: link to owner, dependency path, or health view
Example template logic:
Risk: High
Evidence:
- touches 3 high-degree files
- sits on 7 dependents
- no test file changed
Suggestion:
- add targeted tests for the edge path in src/foo/bar.py
That is enough. If you need a paragraph, the bot is doing too much.
If you want to see the sort of output this style produces, compare the auto-generated docs for FastAPI with the architecture view. The same structure that helps documentation also helps review. The bot is reading the repo the way a good maintainer does: by file, symbol, and dependency path.
Latency budget: less than 10 seconds per PR
A review bot that takes a minute to respond is a bad bot. People will comment manually before it finishes.
The budget needs to be obvious from the start:
| Stage | Target |
|---|---|
| Webhook receive + auth | < 200 ms |
| Diff fetch | < 500 ms |
| Parse touched files | < 2 s |
| Graph query + scoring | < 3 s |
| Render + post comment | < 1 s |
| Buffer for retries | < 3 s |
| Total | < 10 s |
That budget is realistic if you cache aggressively. The dependency graph should be precomputed. The git intelligence index should be incremental. The bot should only reparse files touched by the PR. The comment renderer should be pure string formatting.
A lot of teams overbuild the online path. They try to compute the world per PR. Do not do that. Build once, query fast.
Idempotency: edit the same comment
PR bots get annoying when they spam duplicate comments. The fix is simple: make the bot own one comment and one check run per PR head SHA.
The workflow should be:
- Search for an existing bot comment on the PR.
- If found, edit it in place.
- If not found, create it.
- Store the comment ID keyed by repository + PR number.
- Treat the head SHA as the version boundary.
GitHub’s Checks API supports creating and updating check runs, which gives you a clean home for structured status output. The same principle applies to review comments. One PR, one thread, one authoritative summary. (docs.github.com)
This matters for trust. Reviewers should be able to glance at a PR and know that the bot is speaking once, not nagging.
Failure modes and silence rules
A deterministic bot should know when not to speak.
Failure modes
- Parse failure in a changed file
- Missing dependency graph snapshot
- History lookup timeout
- Diff too large for the configured budget
- Unsupported language
- Ambiguous symbol mapping
Each of these should have a bounded response. Do not invent a review. Post a short operational note or fail the check run with a clear reason.
Silence rules
Silence is the right answer when:
- the score stays under threshold
- no high-risk symbols changed
- no tests are missing for the touched area
- the PR only updates docs or configuration
- the graph shows no new coupling risk
This is where deterministic systems beat chatty ones. If the bot has nothing grounded to say, it should say nothing.
What not to do
Do not auto-hallucinate style feedback. Do not invent refactors. Do not guess at intent. A no llm code review system that speculates is worse than no bot at all.
Lessons learned shipping to GitHub Marketplace
If you plan to ship this as a GitHub App, read the Marketplace requirements early. GitHub’s Marketplace docs cover listing creation, approval, and the app review flow, and the platform expects a real product experience before publication. (docs.github.com)
The biggest lesson is that Marketplace users want deterministic behavior even more than internal users do. They are installing a bot into someone else’s workflow. That means:
- clear install steps
- clean permission scope
- predictable output
- no hidden model costs
- no surprise network dependencies
A deterministic PR review bot helps here because the product story is easy to explain. The bot analyzes code, git history, and dependency structure. It writes one comment. It never calls an LLM. That is easy to test and easy to support.
This is also where an open source PR bot has an advantage. Users can inspect the logic, self-host it, and adapt the thresholds. Repowise’s AGPL-3.0 stance keeps that path open, and the project’s architecture page lays out how the intelligence layers fit together.
 Marketplace Installation Flow
Marketplace Installation Flow
Why zero LLM calls is a feature, not a constraint
A lot of review tools start with “let the model read the diff” and end with prompt churn. That path looks fast because the first demo works. It gets expensive later, when output changes from run to run and nobody can tell whether a comment is useful or just plausible.
Zero LLM calls forces discipline.
You have to define the signals. You have to bound the score. You have to explain the result. You have to test the output.
That discipline pays off in review quality. The bot becomes a static piece of infrastructure, closer to a linter than a chat assistant. It is easier to run in CI, easier to self-host, and easier to trust.
FAQ
What is deterministic PR review?
It is PR feedback built from fixed rules, code structure, and repo data instead of model-generated text. The same input produces the same output.
How is no LLM code review different from AI code review?
A no LLM code review bot uses static analysis, graphs, and git history. An AI code review bot usually infers feedback from a language model. Deterministic systems are easier to test and debug.
What should a GitHub bot architecture include for PR review?
At minimum: webhook intake, diff fetch, parser, dependency graph, scoring engine, comment writer, and idempotent storage for review state. GitHub’s Checks API is the cleanest place to post structured status output. (docs.github.com)
How do you score code health in a PR bot?
Use measurable signals: churn, complexity, dependents, co-change pairs, ownership breadth, missing tests, and dead-code exposure. Normalize each signal and combine them with explicit weights.
Can an open source PR bot be useful without an LLM?
Yes. For many repos, the highest-value review signals are structural, not generative. Dependency paths, hotspot touches, and ownership conflicts are all deterministic and often more actionable than a model’s prose.
Why use Tree-sitter and NetworkX together?
Tree-sitter gives you syntax-aware parsing across languages. NetworkX gives you graph queries over the parsed structure. Together they turn a codebase into a map you can score and explain. (tree-sitter.github.io)
 Code Health Scorecard
Code Health Scorecard
If you want to try this pattern on a real repo, start with the FastAPI dependency graph demo and compare it to the live examples. The value is easiest to see when the data is concrete.