Why vector-only retrieval misses co-change clusters in monorepos
A vector index will happily tell you that service.py is “close” to helpers.py because both say “request”, “response”, and “client”. Then a monorepo refactor lands, the API contract shifts, the test fixture breaks, the migration needs a tweak, and the file that actually mattered was openapi.yaml. That is the basic failure mode of vector-only retrieval in monorepo refactors: it optimizes for semantic similarity when the real question is co-change analysis git history — which files move together, who tends to touch them, and what breaks next.
That distinction sounds academic until you are the person trying to land the change without waking up three teams.
Vector search can find similar code, but it cannot tell you which files fail together
Vector search is good at finding lookalikes. It is bad at finding the files that actually fail together.
A concrete example:
service.pyandhelpers.pyboth talk about serialization, retries, and request validation.openapi.yamlandtest_service.pybarely share vocabulary withservice.py.migration.sqlshares almost none of it.
If you ask a vector index for “related files,” it will often rank helpers.py above openapi.yaml and migration.sql. That is plausible on paper. It is also the wrong answer if the next change is a renamed endpoint, a schema tweak, or a request shape change.
Semantic similarity answers “what looks alike?” while co-change answers “what moves together?”
That is the whole argument.
The reason this matters in monorepo refactors is that the risky edge is usually not the source file with the most words in common. It is the contract file, the migration, the config, or the test that has historically moved in lockstep with the code you are changing. graph communities and execution flow is useful here because it shows how a codebase is shaped; co-change analysis git history shows how it actually behaves over time.
 SEMANTIC SIMILARITY VS CHANGE COUPLING
SEMANTIC SIMILARITY VS CHANGE COUPLING
A retrieval system that only knows embeddings is basically saying: “show me the neighbors.” A refactor asks a different question: “show me the blast radius.”
Co-change clusters appear before ownership is obvious
The useful thing about co-change analysis is that it does not wait for organizational truth to become explicit.
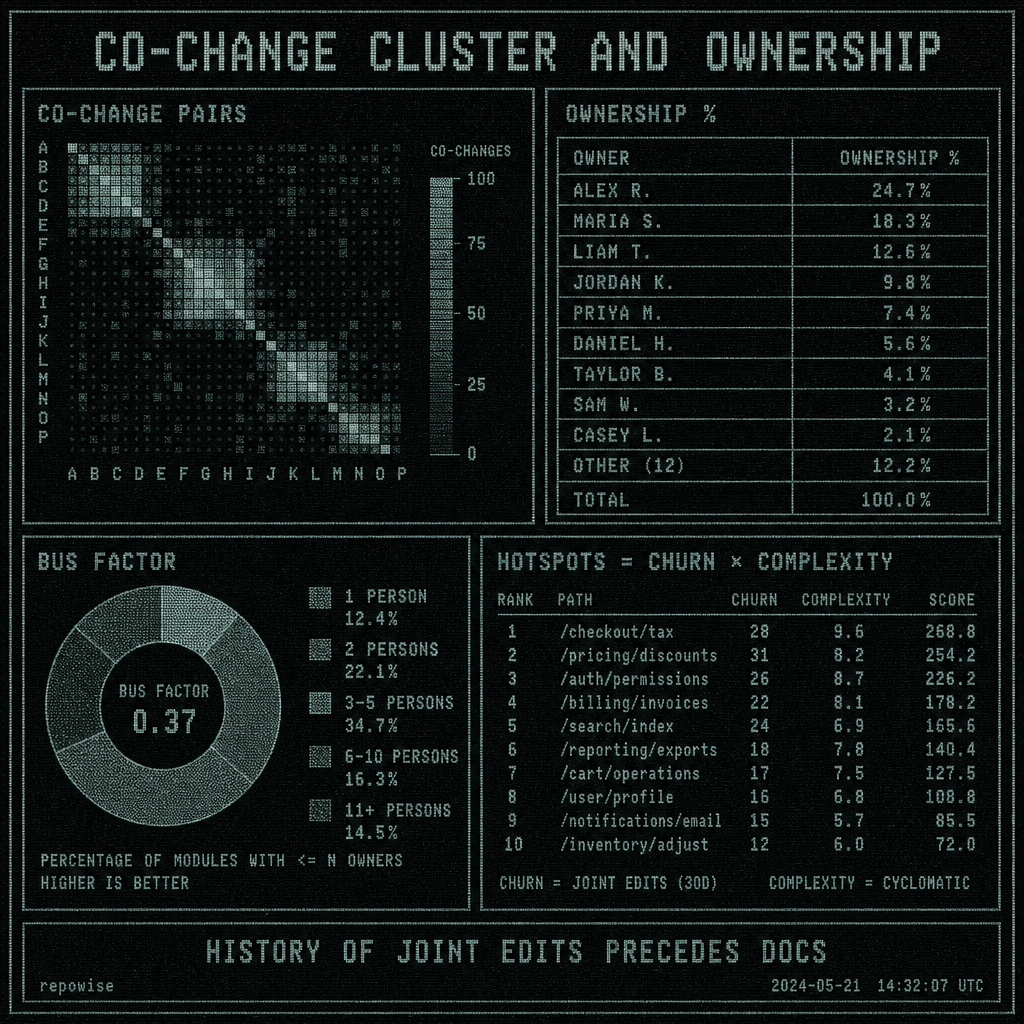
Repeated joint edits are an early warning signal. They tell you there is a hidden module boundary, a shared release surface, or an informal owner that has not made it into CODEOWNERS yet. In git history, those patterns show up as co-change pairs, churn, ownership %, bus factor, and hotspot scores. hotspots, ownership, and bus factor is the right mental model because it turns “who owns this?” into a historical question instead of a naming convention.
That matters because ownership docs lag reality. Team boundaries move. A repo can be “owned” by one group on paper and effectively maintained by whoever last fixed the flaky tests. Co-change clusters often precede explicit ownership docs or team boundaries by weeks or months.
A few concrete signals:
- two files are touched together across many commits, even when the commits are not large
- the same small set of people keeps editing the same cluster
- one file has high churn and high complexity, but the apparent owner set is tiny
- a change in one file repeatedly triggers edits in a test, config, or contract file
That is not just correlation. It is a map of the maintenance surface.
The literature has described this shape for years under names like co-change patterns and evolutionary coupling. The old SERP paper on co-change patterns is useful because it names the cluster shapes you keep seeing in practice. A more recent caveat is worth keeping in mind too: the 2026 paper on code co-committal argues that co-change signal quality varies by repository behavior. That matches what many of us have seen informally. Some repos have clean, stable coupling. Others are noisy, chore-heavy, or dominated by broad mechanical edits.
So no, co-change is not magic. But it is usually better than pretending similarity is the same thing as coupling.
 CO-CHANGE CLUSTER AND OWNERSHIP
CO-CHANGE CLUSTER AND OWNERSHIP
freshness-scored wiki pages helps with the “what do we know?” question, but co-change answers the more operational one: “what is likely to move when this changes?”
A refactor walkthrough: the files that moved together, not the files that looked similar
Here is the kind of cluster that should change how you plan a refactor.
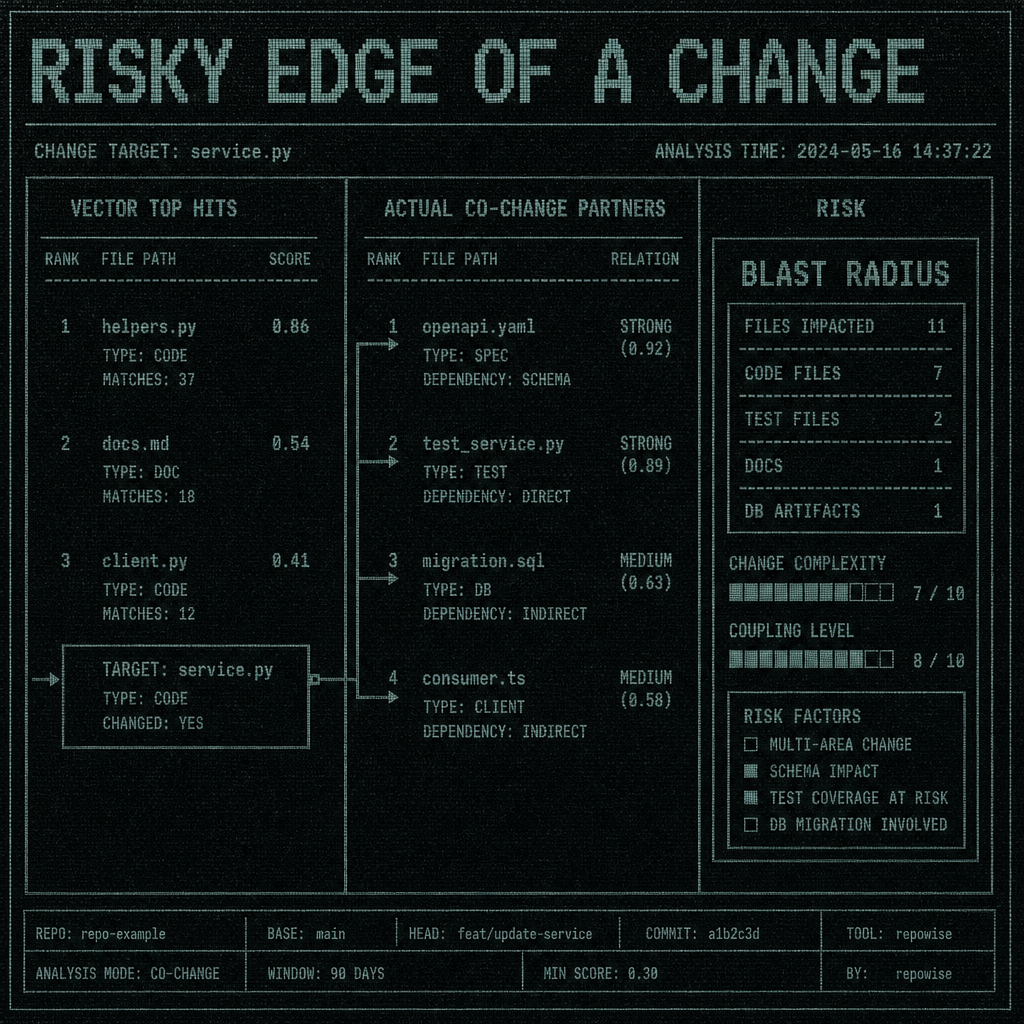
Suppose you are renaming a service endpoint and changing the response shape in a monorepo. The actual co-change cluster looks like this:
service.pyopenapi.yamlmigration.sqltest_service.pyconsumer.ts
Only two of those are lexically similar to the source file. The others matter because they move with it.
| File / group | Why vector search would rank it | Why co-change says it matters |
|---|---|---|
helpers.py | Shares vocabulary like request, response, serialize | Looks similar, but has not historically moved with this endpoint |
docs.md | Mentions the same feature terms | Useful for docs, not the risky edge |
openapi.yaml | Less lexical overlap than helper code | Contract file; often changes when request/response shape changes |
test_service.py | Similar names, so maybe moderately ranked | Historical partner in every shape or behavior change |
migration.sql | Usually low semantic similarity | Breaks when payload or schema semantics shift |
consumer.ts | Often under-ranked unless it contains the same nouns | Downstream contract consumer; can reveal blast radius |
The real blast-radius indicator is openapi.yaml or consumer.ts, not helpers.py. If you miss that, the agent plans the wrong sequence, asks for the wrong files, and hands you a review set that looks reasonable but misses the edge of the change.
What surprised us initially was how often the “obvious” source file was not the most useful anchor. We expected embeddings to help with the first hop, and they do. But on actual refactors, the highest-value files were often the ones with the least lexical overlap: tests, config, schema, and migration artifacts.
That is not a bug in embeddings. It is a mismatch between the retrieval primitive and the question.
Here is a more concrete “what embeddings ranked highest vs what actually broke” list:
- embeddings ranked
helpers.py - embeddings ranked
docs.md - embeddings ranked
client.py - actually broke:
openapi.yaml - actually broke:
test_service.py - actually broke:
migration.sql
That is the risky edge in plain sight.
If you want a structured way to inspect this kind of cluster, LENS-style structured code queries are useful because they surface cross-cutting concerns that grep misses. decision history with get_why() becomes especially helpful once the cluster raises the question “why is this shaped this way?”
Where embeddings mis-rank the risky edge of a change
The failure pattern is consistent enough to be annoying.
Embeddings over-rank:
- lexical neighbors
- docs and examples
- utility code with shared terminology
- “similar-looking” handlers or clients
Embeddings under-rank:
- YAML contracts
- SQL migrations
- tests
- generated interface files
- config that encodes behavioral coupling
That is because embeddings are optimized for semantic neighborhood, not evolutionary coupling. A contract file can be the most important file in the cluster and still look semantically boring. A migration can be the file that determines whether the deploy succeeds and still have little textual overlap with the implementation.
For agent planning, that means the wrong files get read first. For reviewer selection, it means the wrong humans get paged first. For impact analysis, it means the blast radius is underestimated until CI tells you the truth.
A useful way to think about it:
- semantic neighbors answer “what should I inspect next if I want more context?”
- historical co-change partners answer “what else is likely to break if I touch this?”
Those are different jobs.
This is why a retrieval stack that only uses embeddings tends to feel smart in demos and thin in production. It can find the nearby exposition, but not the maintenance surface. And the maintenance surface is what you care about when the repo is large enough that no one remembers all the implicit contracts.
 RISKY EDGE OF A CHANGE
RISKY EDGE OF A CHANGE
This is also where git intelligence features start to matter. Co-change pairs, ownership %, and bus factor are not decorative metadata; they are the difference between “I found some similar code” and “I know who should review this and what else might fail.”
When co-change beats similarity, and when it does not
The best retrieval stack combines both, but not as equals.
Use co-change when:
- you are planning a refactor
- you need impact analysis
- you are trying to discover ownership
- you are choosing tests and reviewers
- you need to estimate blast radius
- you are looking for files that historically break next
Use embeddings when:
- you are doing first-pass code discovery
- you are looking up a concept by meaning
- the repo has sparse history
- the code is brand new
- you need a broad semantic search over docs and implementation
A simple decision matrix:
| Question | Prefer co-change | Prefer embeddings |
|---|---|---|
| Which files move together in a refactor? | Yes | No |
| Who really owns this area? | Yes | Sometimes |
| What should I read first in a new subsystem? | No | Yes |
| Which test files usually accompany this change? | Yes | No |
| What does this concept mean in the codebase? | No | Yes |
| What about a brand-new module with no history? | Weak | Yes |
The caveat matters: co-change is weaker in sparse-history repos, brand-new code, and one-off changes. If a file has only a handful of edits, the historical signal is thin. If the repo is full of sweeping mechanical changes, co-change can get noisy. That is why the best systems treat it as a stronger signal for impact and coordination, not a universal replacement for semantic search.
If you want a concrete implementation reference, tools like Repowise, Sourcegraph, and DeepWiki take different shots at this problem. Repowise’s Git Intelligence surfaces co-change pairs, ownership %, hotspots, and bus factor, while its workspace mode extends that across repos with cross-repo co-change pairs and API contract extraction.
For teams using agents daily, that difference is not cosmetic. It changes whether the agent asks for “similar files” or “historical change partners.”
FAQ
What is co-change analysis in git history?
Co-change analysis is the study of which files are edited together over time. It treats git history as evidence of evolutionary coupling: if two files repeatedly change in the same commits, they likely participate in the same behavior, contract, or maintenance boundary.
Why does vector search miss co-change clusters in monorepos?
Because vector search ranks semantic similarity, not change coupling. In monorepos, the files that actually move together are often contracts, tests, migrations, and config files that share little vocabulary with the implementation file, so embeddings under-rank the risky edge of the change.
When should I use co-change analysis instead of embeddings for code search?
Use co-change analysis for refactors, impact analysis, ownership discovery, reviewer selection, and test planning. Use embeddings for concept lookup, first-pass discovery, and repos where history is sparse or the code is too new for coupling to have emerged.
How do I find files that change together before a monorepo refactor?
Start from the target file, pull its historical co-change partners from git history, and rank them by frequency, churn, and ownership concentration. Then inspect the contract, migration, test, and config files that repeatedly appear in the same commit set, because those are usually the actual blast-radius indicators.