AI Code Review Tools Fail When They Ignore Ownership
A PR can pass lint, pass tests, and still be a bad review. That is the part most ai code review tools miss: not syntax, not formatting, but the ownership blind spots that tell you whether you are the right person to comment at all. I keep seeing reviews where the model notices a missing null check in a Flask handler, while the real question is whether the change touches a hot auth path that another team has been churning for three weeks.
A clean diff can still be a bad review when the reviewer has no ownership signal
Here is the failure mode. A route handler in app/routes/payments.py changes a serialization field. The diff is small. CI is green. The bot says “consider adding a guard for None” and “this function is getting long.” Technically true. Practically useless.
The reviewer who gets pinged is whoever owns the file path by convention, not whoever has the local memory to know that this endpoint sits behind a brittle auth helper and was already touched twice this week. That is the difference between code correctness and review routing. Correctness asks whether the patch compiles and behaves. Routing asks who should see it first, and what context they need before they trust the diff.
This is why CODEOWNERS-style assignment is only a starting point. It encodes file ownership, not review expertise. The person with the best local memory is often the one who just fixed the adjacent module, not the nominal owner of the directory.
The phrase I keep coming back to is ownership blind spots. A review system can be “smart” about the diff and still blind to the social and historical map of the codebase.
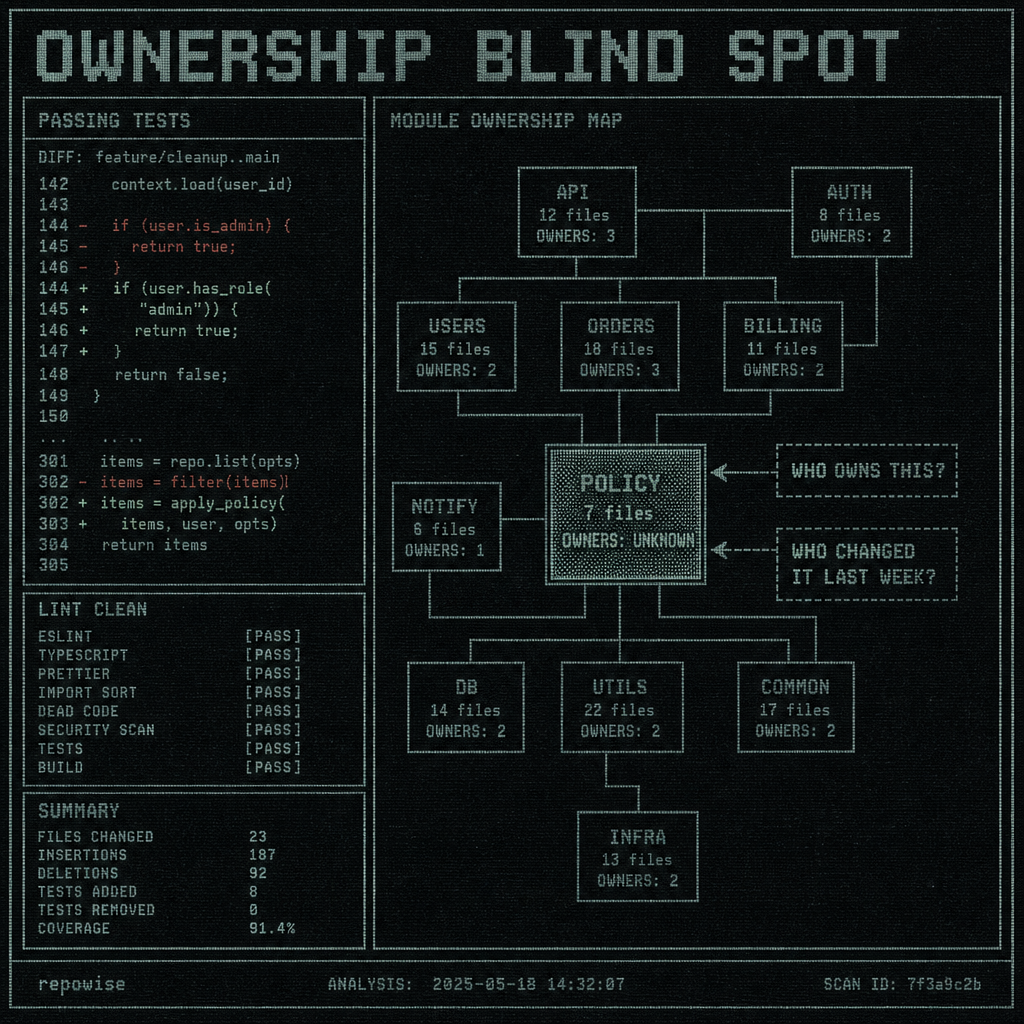 OWNERSHIP BLIND SPOT
OWNERSHIP BLIND SPOT
Why syntax-aware AI code review tools are the easy part
Most ai code review tools are strongest at the easiest layer of review. They summarize diffs, catch formatting drift, spot missing null checks, and flag obvious anti-patterns. That is useful. It is also the lowest-value part of the job.
If a bot tells you a variable is unused, that is fine. If it tells you a method is too long, that is fine too. If it points out a missing guard on an input path, great. But none of those checks answer the questions that usually decide whether a review is worth reading:
- Who should review this?
- What changed nearby?
- Is this area already unstable?
- Does the reviewer have any local history to trust?
That last one matters more than people admit. A reviewer who has touched the same symbols for the last month can often spot the real regression faster than a generic model can summarize the patch. A diff without context is just text. Review is a judgment about place, not just code.
This is where a lot of AI review products stop. They can be very good at “what changed.” They are much less good at “who knows this area” and “why is this change sitting here.”
A useful comparison is not “does the tool generate comments?” It is “does the tool know when to stay quiet, when to route elsewhere, and when to attach evidence from local history?”
The three contexts a reviewer needs before commenting
The minimum stack is smaller than teams think, but it is not zero.
Ownership
Ownership means who usually touches this area and who is most likely to know the invariants. Not just the nominal owner in a file map, but the people with real operational memory. If a shared auth helper has been touched by backend, platform, and security in the last quarter, the right reviewer is usually the person who knows why those changes happened, not the one whose name appears in a directory rule.
Local history
Local history means recent commits, co-changes, and repeated churn in the same files or symbols. If a route and its database model have moved together three times, that is a signal. If a function has been edited every other day, that is a signal too. Repeated churn is often a better review cue than the current diff because it tells you where the codebase is still settling.
Architectural context
Architectural context means dependencies, callers, callees, and why the change sits where it does. A handler is not just a handler. It may be an entry point into a workflow, a shared utility, or a seam between services. Review quality goes up when the tool can explain the surrounding graph, not just the changed lines.
Repowise’s codebase intelligence layer is built around this exact stack: graph intelligence for structure, git intelligence for history, documentation intelligence for living docs, and decision intelligence for why things were done. That is not a product pitch so much as a reminder that review needs memory.
 THREE CONTEXTS BEFORE COMMENTING
THREE CONTEXTS BEFORE COMMENTING
Worked example: the same PR gets different review quality with and without context enrichment
Take a concrete change: a Flask route in a hot area updates a shared auth helper and a SQLAlchemy model used by two other services. The diff is small enough that a naive reviewer thinks it is a routine refactor. The local history says otherwise: the same route, helper, and model have co-changed repeatedly over the last few weeks.
That is where review context enrichment matters. The diff does not change. The review does.
| Situation | Naive AI review comment | Context-enriched review comment | Who should see it first |
|---|---|---|---|
app/routes/session.py changes a token field | “Consider adding a null check for user.” | “This route sits in a hot auth path. The token shape changed twice in the last 10 commits, and the session helper has co-changed with the model. Please confirm the serialization contract before merging.” | The engineer who last touched auth/session flow |
models/account.py updates a shared column | “This rename may affect references.” | “This model has three recent co-changes with the billing route and one with the webhook consumer. Review the callers in the graph before accepting the rename.” | The reviewer with recent billing or webhook history |
utils/permissions.py adds a helper | “This function could be simplified.” | “This helper is imported by five entry points and is part of a repeated churn cluster. The main risk is not style; it is whether the new branch changes behavior for the admin path.” | The person who owns the dependent entry points |
The point is not that the enriched comment is longer. It is that it is more specific about risk, and it routes to someone who can actually answer it.
A short workflow looks like this:
diff arrives
→ fetch ownership and local history
→ fetch architectural context
→ adjust comment confidence
→ route to the reviewer with the best local memory
That is review context enrichment in practice. It turns a generic diff summary into a recommendation with a destination.
Repowise does this with task-shaped MCP tools such as get_context and get_risk, plus PreToolUse hooks that inject related files before a search even starts. The important bit is not the number of tools. It is the fact that context arrives before the human makes a bad guess. See also review context enrichment.
What CodeScene, Sourcegraph, and Copilot get right — and where they stop
These tools are often mentioned in the same breath, but they solve different parts of the workflow.
| Tool | Ownership | Local history | Architectural memory | Review routing |
|---|---|---|---|---|
| CodeScene | Strong on hotspots and change coupling | Strong on churn and risk signals | Moderate, mostly through code health views | Partial, usually advisory |
| Sourcegraph | Strong on code search and cross-repo lookup | Moderate, depends on how you query | Strong for finding related code quickly | Weak by itself, because search is not routing |
| Copilot | Strong in-editor assistance and PR help | Weak to moderate, depending on the surface | Weak unless the surrounding context is already provided | Weak; it helps write comments more than choose reviewers |
CodeScene is the closest to the “what areas are risky?” question. Its hotspot analysis is useful when you want to know where churn and complexity overlap, which is why it pairs well with hotspot and ownership signals. But hotspot detection is not the same as review assignment.
Sourcegraph is excellent when you need to find references, jump across repos, or answer “where else does this symbol live?” That makes it a strong search and navigation layer. But search is not a review policy. It helps the reviewer find context; it does not tell the reviewer whether they are the right person to comment.
Copilot is good at generating suggestions in the editor and helping with PR assistance. It can draft a review comment faster than a human can type one. That is helpful, but it is still downstream of the real question: should this comment exist, and who should receive it?
None of these, by themselves, close ownership blind spots.
Where a codebase intelligence layer changes the review loop
The right place to fix review is not after the bot has already emitted a generic comment. It is before or during review, when the system can enrich the diff with local memory and route it correctly.
That is the job of a codebase intelligence layer. In Repowise, the four layers fit together cleanly:
- Graph intelligence tells you what depends on what, which symbols matter, and which entry points trace into the change.
- Git intelligence tells you who has been changing this area, how often, and with what co-change pattern.
- Documentation intelligence gives you a living wiki with freshness and confidence scoring, so the reviewer is not reading stale tribal knowledge.
- Decision intelligence captures why a decision exists in the first place, then links it back to the relevant graph nodes.
That combination is what review systems usually lack. A diff alone cannot tell you whether a change is risky because it is syntactically odd or because it lands in a cluster of repeated churn. A graph plus git history can.
Repowise exposes that through MCP tools like get_context, get_risk, and get_why, and through PreToolUse hooks that enrich Grep and Glob with related files before the agent starts guessing. The goal is not more generated text. The goal is better routing and better comments.
If you are working across repositories, the same logic gets even more important. Cross-repo co-changes and API-contract extraction make it harder for a reviewer to rely on memory alone, which is why cross-repo intelligence matters once a team has more than one codebase to keep in its head.
 REVIEW LOOP WITH CONTEXT ENRICHMENT
REVIEW LOOP WITH CONTEXT ENRICHMENT
We got this wrong initially in a very normal way: we thought the main win would be fewer comments. It turns out the bigger win is fewer wrong comments sent to the wrong person. That sounds minor until you watch a senior engineer spend ten minutes dismissing a bot’s generic warning on a file they barely know, while the person who last changed the area never saw the review.
The review failure mode to fix first is not missed syntax; it is missing trust
If you are evaluating ai code review tools, do not start with comment volume. Start with trust.
A good decision rule for engineering managers and staff engineers is simple: if the tool cannot identify the likely owner, explain the nearby churn, and cite local history for the area it is commenting on, do not let it drive review routing. Put it in the PR bot only if it can see ownership and history. Otherwise it becomes a polite noise generator.
That evaluation rule is stricter than “does it find bugs?” because bug-finding is not the bottleneck. Trust is. Teams adopt review automation when it helps them trust the right human, the right area, and the right explanation. They churn on it when it produces plausible comments without memory.
This is why the best use of ai code review tools is not as stand-alone judges. It is as part of a system that knows the codebase, the recent past, and the people who actually carry the context.
FAQ
Why do AI code review tools miss ownership context?
Because most of them operate on the diff and nearby text, not on the codebase’s social and historical structure. They can see what changed, but not who has been living in that area or who recently changed adjacent symbols.
How does review context enrichment improve AI code review?
It adds ownership, local history, and architectural context before the model comments. That makes the comment more specific, improves confidence, and often routes the review to the person with the best local memory.
What is the difference between local history and architectural context in code review?
Local history is about recent commits, co-changes, and churn in the same files or symbols. Architectural context is about dependencies, callers, callees, and how the change fits into the system shape.
Should AI code review live in the PR bot, the IDE, or the codebase layer?
The PR bot is where comments surface, but the codebase layer is where context should come from. The IDE can help while writing, but if the system cannot see ownership and history, the bot will still misroute the review.
What should teams measure when evaluating AI code review tools?
Measure whether the tool finds the right owner, explains nearby churn, and cites local history before it comments. If it only increases comment count, it is optimizing noise, not review quality.


