When an MCP tool should return raw text, not answers
I keep seeing the same failure mode in mcp tools design: a tool gets asked for evidence, and it answers the question instead. That feels efficient until the model needs to inspect the underlying file, symbol, or decision and finds only a tidy paraphrase. By then, the proof is gone, and agent over-summarization has already done its quiet damage.
When we built Repowise’s MCP surface, that boundary became the main design question. Not “how do we make every tool smart?” but “where should the tool stop, and where should the model start?”
The fastest way to make an MCP tool worse is to answer the question for the model
The easiest way to ship a bad MCP tool is to wrap a search result in a sentence that sounds useful.
A concrete example: a tool is asked, “what changed in this commit?” and returns, “This commit refactors request handling to centralize validation and reduce duplication.” That sounds plausible. It may even be correct. But it has already collapsed the evidence into an interpretation, which means the model cannot verify whether the real change was a renamed function, a new caller path, or a deleted guard clause.
That is the core mistake: the tool acts like the brain, and the model becomes a reader of summaries instead of a reasoner over evidence. The result is agent over-summarization. The model starts seeing one layer of abstraction too early, and every downstream judgment gets less reliable because the raw material is thinner than it should be.
This is why we treat codebase intelligence for AI coding agents as a retrieval problem first, not an answer factory. Repowise’s seven task-shaped MCP tools are intentionally shaped around work the agent actually needs to do, not around making the response look polished.
 EVIDENCE FIRST, ANSWER SECOND
EVIDENCE FIRST, ANSWER SECOND
Raw context is not a missing feature; sometimes it is the product
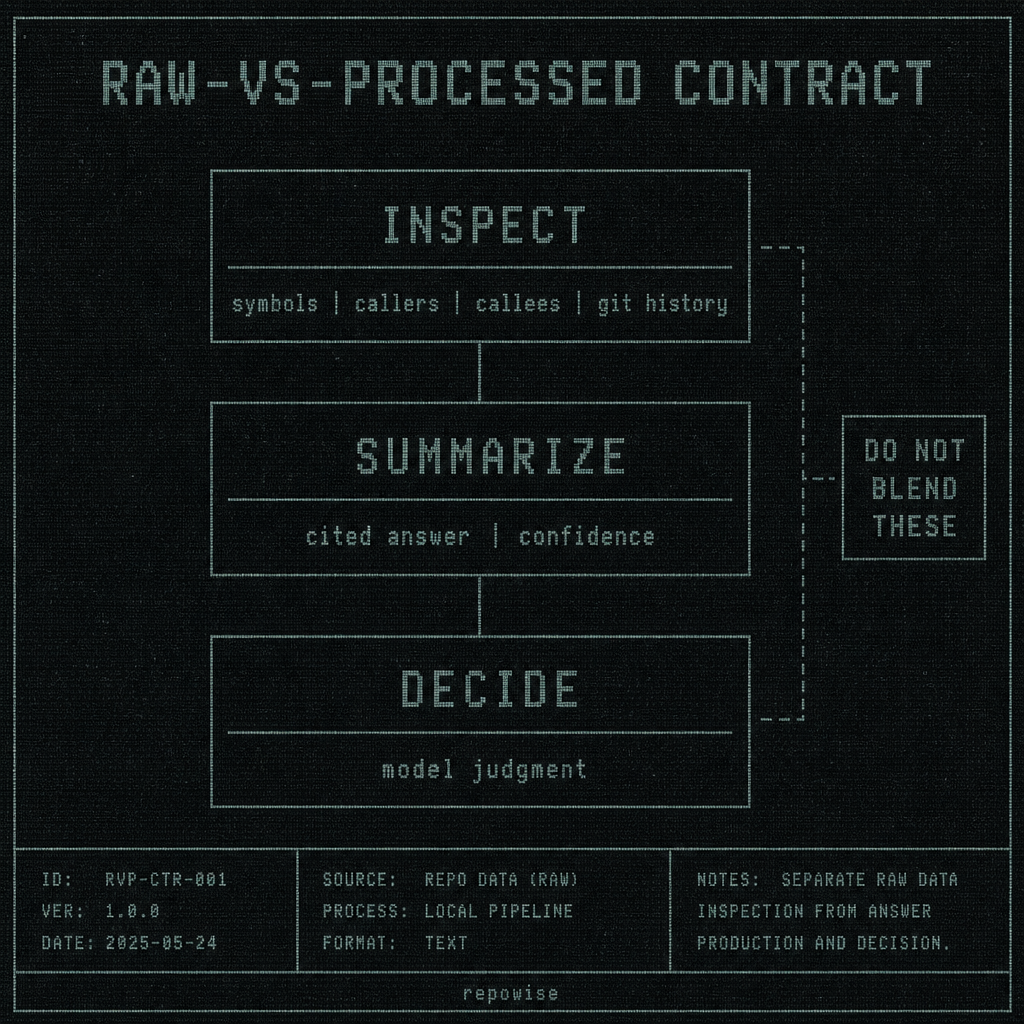
There is a useful raw-vs-processed tool contract hiding in plain sight.
Raw means the tool returns inspectable evidence: file paths, symbols, callers, callees, git commits, ownership, decision records, or exact source slices. Processed means the tool returns a bounded interpretation: a short answer, a confidence score, a synthesized explanation, maybe with citations. The mistake is treating processed output as the default for everything.
The hard line is this: inspect, summarize, decide are different operations.
If the user is inspecting, return raw. If the user is summarizing, return a bounded synthesis with pointers back to source. If the user is deciding, let the model decide after it has seen the evidence.
One example involving code symbols, callers, and git history: a user asks, “who owns this endpoint?” The wrong answer is “the payments team.” The right raw response is the endpoint’s symbol, the files that define it, recent commits touching it, co-change partners, and ownership percentage over the configured history window. Ownership is not a vibe. It is an inference the model should be allowed to test against evidence.
That is why Repowise splits ownership, freshness, and communities from interpreted retrieval. get_context is allowed to be raw and specific. It can return docs, symbols, ownership, freshness, and communities for a target. It does not need to pretend to know which interpretation the user wants. That restraint is the feature.
 RAW-VS-PROCESSED CONTRACT
RAW-VS-PROCESSED CONTRACT
Where summarization belongs, and where it breaks trust
Summarization is not bad. Premature summarization is bad.
The narrow cases where a summary helps are pretty clear: after retrieval, when the tool can preserve citations; when the tool can attach confidence; or when the user explicitly asked for a synthesized answer instead of evidence. Repowise’s get_answer exists for exactly that reason: a confidence-gated cited answer that collapses search, read, and reason into one step when the question is already answer-shaped. That is very different from a tool that summarizes everything by default.
Here is the contrast that matters:
- confidence-gated answer: “Here is the best-supported answer, and here are the sources”
- raw evidence: “Here are the symbols, files, commits, and links; decide what they mean”
Summaries break trust when the question is ambiguous, ownership is disputed, docs are stale, or the answer needs a chain of reasoning that the user may want to audit later. Stale or incomplete documentation is a strong reason not to over-summarize. If the wiki is behind the code, a smooth paragraph is worse than a noisy but honest set of pointers.
That is also why summaries should preserve citations or pointers back to source. A summary without source references is just a rumor with formatting.
Repowise’s documentation layer is built around freshness scoring for exactly this reason, and the post-commit hook exists to flag staleness instead of pretending the wiki is always current. The point of PreToolUse/PostToolUse hooks is not to be clever in the abstract; it is to keep the evidence trail intact when the code changes.
Three tool shapes that should stay boring: list, slice, cite
When I’m reviewing an MCP server, I usually ask whether its tools fall into three boring shapes.
- List: enumerate the relevant things.
- Slice: return the raw excerpt or structured evidence for one thing.
- Cite: return a bounded answer with explicit source refs.
That is enough for most codebase tasks. It also keeps the tool from inferring intent when the user asked to inspect.
Repowise maps cleanly onto these shapes:
get_overviewis a list-shaped first pass over an unfamiliar repository.get_contextis a slice-shaped workhorse for symbols, ownership, freshness, and related context.get_answeris a cite-shaped retrieval tool for when the user really wants the synthesis.get_whyis the decision-shaped path into architectural rationale.get_dead_codeis deliberately non-LLM and stays in the graph/SQL lane.
This is the part many MCP tool authors get wrong: they try to make one tool do all three jobs. The result is a mushy interface where every response is half evidence, half interpretation, and nobody can tell which layer they are holding.
A good MCP server should be more boring than that. The model can do the interesting part.
Worked example: the same question answered three ways by an MCP tool
Take one concrete question: “why did this commit change X?”
| User question | Raw tool response | Over-summarized tool response | Why the raw version is better for the model |
|---|---|---|---|
| why did this commit change X? | commit: 8f3c2d1<br>files: api/routes.py, api/auth.py<br>changed symbols: validate_token(), require_scope()<br>callers: router.handle_request(), middleware.auth_check()<br>co-change: tests/test_auth.py, docs/auth.md<br>message: "tighten auth path after incident" | “This commit strengthens authentication by centralizing validation after an incident.” | The model can inspect the exact symbols, see the caller graph, compare co-changes, and decide whether the summary is true. The over-summarized version hides the proof and makes verification impossible. |
That table is the whole argument in miniature.
The raw response gives the model room to reason. It can inspect the changed symbols, trace callers, compare commit messages, and decide whether the change was security-related, cleanup-related, or both. The processed answer may be correct, but it forces trust before inspection.
Repowise’s get_context is designed for this exact kind of work: return the evidence around a target, not a verdict about it. If the user wants a verdict, get_answer can provide one with citations. If they want the evidence, get_context should stay raw.
A practical decision rule for tool authors: if the model still needs to inspect, return raw
Here is the rule I wish more MCP servers followed:
- If the user is asking to inspect evidence, return raw.
- If the user is asking for a cited answer, return a bounded summary.
- If the user is asking for judgment, let the model decide.
That is the cleanest line I know for mcp tools design.
A short checklist for tool authors shipping MCP tools:
- Does the response contain source refs, not just a paraphrase?
- Could the model verify the claim from the returned data?
- Is the task inspectable code, diff, ownership, decision history, or architecture?
- Would a summary hide uncertainty, stale context, or missing links?
- If the user asked “what changed,” are you returning evidence or interpretation?
If the answer still requires inspection, don’t pre-decide it in the tool. Interpretive tasks belong to the model, not the tool.
A useful pseudo-contract looks like this:
{
"raw_text": "...",
"citations": [
{"path": "api/routes.py", "line_start": 42, "line_end": 88}
],
"confidence": 0.87,
"source_refs": [
"git:8f3c2d1",
"symbol:validate_token"
]
}
The point is not that every tool must return JSON like this. The point is that raw_text should not be replaced by a paraphrase when inspection is the goal.
That distinction shows up in Repowise’s own shape. get_overview is for orientation. get_context is for evidence. get_answer is for a confidence-gated cited answer. get_why is for decisions. get_risk is for blast radius and reviewer context. get_dead_code is pure graph and SQL, no LLM at all. The tool boundary is doing real work.
 THREE BORING TOOL SHAPES
THREE BORING TOOL SHAPES
What surprised us early on was that the raw tools often felt less polished in demos and more useful in actual agent runs. We initially tried to make some responses read like mini blog posts. People liked the first impression, then the agent immediately asked follow-up questions because the summary had hidden the exact file, the exact symbol, or the exact decision record. The more we stripped the evidence away, the more the model had to go back and ask again.
That is the tradeoff. A raw response is less flattering. It is also more durable.
FAQ
When should an MCP tool return raw text instead of an answer?
When the user is asking the model to inspect evidence: files, symbols, callers, history, ownership, or decisions. If the model still needs to verify the claim, return raw or near-raw context first.
What is the raw-vs-processed tool contract in MCP tools design?
Raw means the tool returns inspectable evidence with source refs. Processed means the tool returns a bounded summary or cited answer. The contract is to keep inspect, summarize, and decide distinct instead of blending them into one response.
How do I stop agent over-summarization in my MCP server?
Make raw the default for inspectable tasks, preserve citations, and gate summaries on retrieval confidence. Also avoid tools that infer intent when the user asked for evidence, because that is where over-summarization usually starts.
Should an MCP tool summarize code or return source evidence?
Return source evidence when the task is inspection, tracing, ownership, or diffing. Summarize only after retrieval, when the answer is confidence-gated and still points back to source. If the docs are stale or incomplete, raw evidence is safer than a polished summary.


