Why we ship a graph-aware MCP server instead of file readers
A file-reader MCP server can answer one question very quickly: where does this symbol appear? A graph aware mcp server answers the question engineers actually care about: who calls it, who depends on it, what else changes if it moves, and who should review it. That difference sounds small until you watch an agent burn through the same file five times and still miss ownership.
The pattern is familiar. The agent greps for parse_request, opens the file, greps for parse, opens the caller, greps again for request, then opens another file because the first one only showed a text match. Nothing is wrong with grep. It is just the wrong primitive when the real question is about neighborhood, not occurrence.
12 grep calls later, the agent still does not know who depends on the function
The failure mode is not subtle. A Claude Code or Cursor session starts with a changed function, asks for the symbol, gets a list of file hits, and then spends the next few turns reconstructing the graph by hand. By the time the agent has opened the third file, it still does not know whether the function is on a hot path, whether another repo consumes it, or whether the owning team is the one that should review the change.
That is the difference between “find occurrences” and “understand the neighborhood.”
A text hit is useful when you want a string. It is a weak signal when you need impact, blast radius, or safe change scope. The moment the question becomes “what depends on this?” file readers stop being efficient because dependence is not a substring problem.
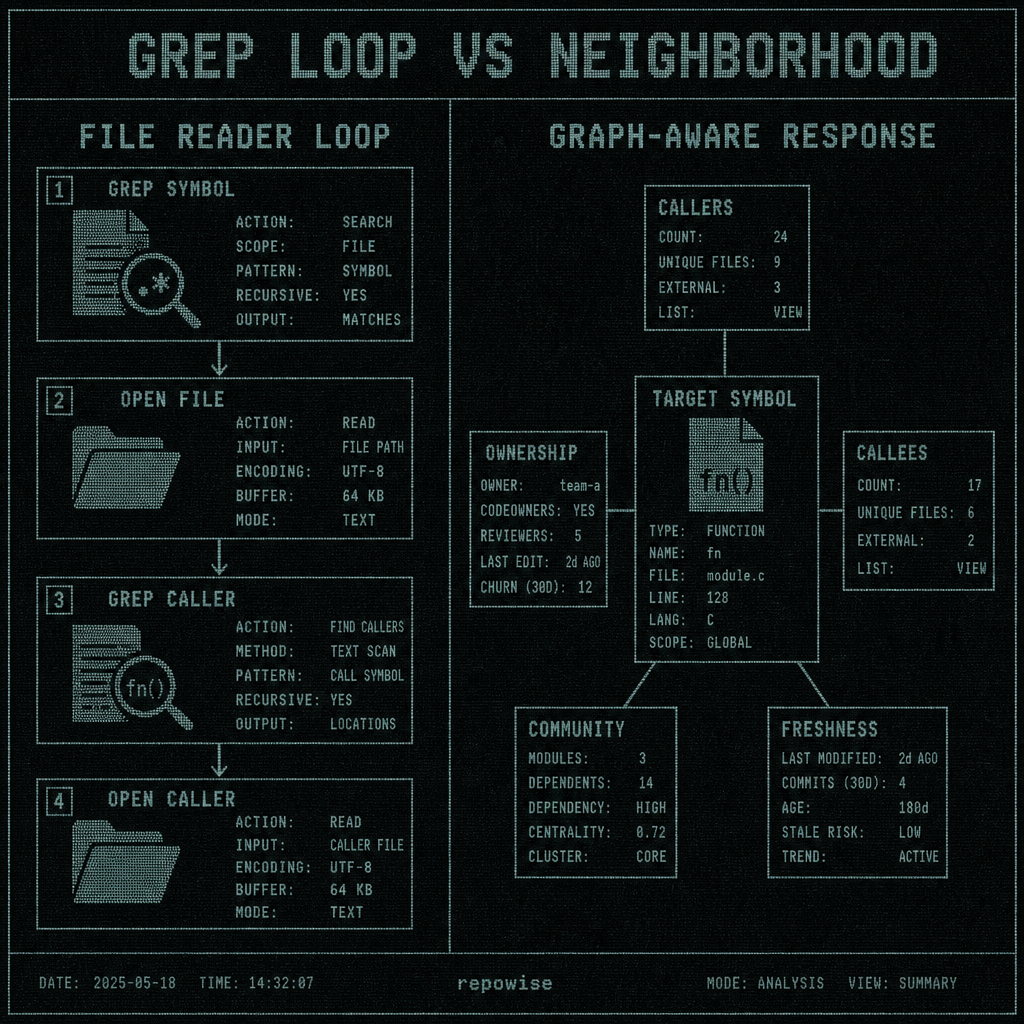 GREP LOOP VS NEIGHBORHOOD
GREP LOOP VS NEIGHBORHOOD
The best way to see it is to stop pretending all code questions are the same. Search is for discovery. Graph is for context. Ownership, freshness, dependents, and nearby modules are context. So is “what else changes if I touch this?” That is why a graph aware mcp server changes the unit of work instead of just the prompt wording.
What graph aware means at the MCP boundary: symbols, callers, dependents, and ownership in one response
At the MCP boundary, graph aware mcp means the server returns structured context around a target instead of just text matches. The underlying shape is a typed callgraph plus related metadata: symbol graph edges, docs, freshness, communities, ownership, and risk signals. The model does not need to infer the neighborhood from a pile of snippets.
That distinction matters. This is not a prompt trick. It is not “please think harder about the grep output.” It is a different data model exposed through MCP.
Repowise’s core tools are shaped around that model:
get_overviewfor the first pass on an unfamiliar codebaseget_contextfor the target plus callers, callees, docs, ownership, freshness, and communityget_riskfor hotspots, dependents, co-change partners, blast radius, reviewers, and test gapsget_whyfor decisions and stalenessget_answerandsearch_codebasewhen the wiki is the right surfaceget_dead_codewhen the question is about reachability, not prose
The interesting part is that the server can also intervene before the model starts wandering. PreToolUse hooks intercept Grep and Glob, then inject the top related files from local SQLite: symbols, importers, and uses. That means even a search-oriented agent gets a nudge toward the graph instead of another blind text pass.
We got one thing wrong initially: we assumed the biggest win would come from smarter answers. It mostly came from fewer wrong turns. The model did not need to become more clever; it needed fewer chances to chase the wrong file.
 GET_CONTEXT RESPONSE SHAPE
GET_CONTEXT RESPONSE SHAPE
Repowise’s four intelligence layers line up with that boundary: graph intelligence, git intelligence, documentation intelligence, and decision intelligence. The point is not to stuff more data into the prompt. The point is to answer the question in one structured response so the agent can stop reading.
Token math: 12 grep iterations versus one get_context call
The token story is not abstract. On the 30 most recent non-merge commits of pallets/flask, Repowise’s token-efficiency benchmark found:
| strategy | tool pattern | tokens read | tool calls | latency | what the agent learns |
|---|---|---|---|---|---|
| naive grep/open loop | grep, open, grep, open, repeat | 64,039 per commit | many | high | text hits, but not the neighborhood |
| git diff | one diff plus follow-up reads | 14,888 per commit | moderate | medium | changed lines, partial context |
one get_context call | target → structured context | 2,391 per commit | 1–2 | low | callers, callees, ownership, freshness, community |
The same dataset gives the headline ratios: 209× mean savings versus the naive loop, 41.7× versus git diff, 26.8× pooled versus naive, and 6.2× pooled versus git diff. The best-case commit was 1,214× smaller than the naive path, which is the kind of number that makes people suspicious in a healthy way.
Those numbers are not magic. They are what happens when the server already knows the neighborhood and does not ask the model to rebuild it from scratch.
A simple worked example makes the shape obvious. Suppose an agent needs to understand a changed function in a medium-sized service.
| step | naive file-reader loop | graph-aware path |
|---|---|---|
| 1 | grep symbol | get_context(target) |
| 2 | open file | callers included |
| 3 | grep caller | callees included |
| 4 | open caller | ownership included |
| 5 | grep second symbol | freshness included |
| 6 | open second file | risk/community included |
| 7-12 | repeat until confidence is high enough | stop |
By the time the naive loop reaches iteration 12, it has usually read the same utility code, imports, and test scaffolding multiple times. The graph-aware response reads the neighborhood once.
That is why the benchmark shows 89% fewer files read and 36% lower cost on SWE-QA, with parity answer quality. The model is not getting weaker. It is getting less redundant work.
Latency math: 14 seconds of round-trips versus 280 milliseconds of context
Tool calls are not free. Each hop adds transport, tool execution, and model waiting time. In a file-reader loop, latency compounds because the agent cannot know what to ask next until it has read the previous file. The loop is serial by construction.
Repowise’s SWE-QA benchmark on pallets/flask showed 49% fewer tool calls and 19% faster wall time, with the same answer quality within measurement noise. That is the important part: the latency drop came from removing turns, not from making the model answer faster in some special way.
Here is the practical version.
| path | typical interaction shape | wall-time effect |
|---|---|---|
| file-reader loop | search → open → search → open → search | multiple round-trips, each dependent on the prior read |
| graph-aware context | one target lookup with structured neighborhood | front-loads the necessary context |
| SWE-QA result | 49% fewer tool calls | 19% faster wall time |
If you use Claude Code or Cursor all day, this is the ergonomics difference you feel. The agent spends less time asking permission to learn the next obvious thing. It gets the neighborhood up front, then spends its budget on reasoning and edits instead of rereading imports.
 TOOL CALL LATENCY COMPARISON
TOOL CALL LATENCY COMPARISON
The latency benefit is also why “just use git diff” is not a satisfying answer. Diffs are useful, but they are still a textual artifact. They show what changed, not the graph around what changed. If the agent has to infer blast radius from a diff, it is still doing graph work manually.
Where file readers still work, and where graph-aware context breaks down
Grep is still fine for trivial lookup. If you are editing a config-only file, checking a single-file script, or confirming a literal string, a file reader is the right tool. If the symbol is obviously local and the change cannot propagate, there is no need to bring a graph to a string fight.
Graph-aware context matters most when the question has externalities:
- refactors that cross files
- ownership questions
- blast-radius checks
- API changes with consumers
- changes where tests live somewhere else
- “why was this done this way?” decisions that are not in the code itself
It also breaks down in predictable ways. Unknown symbols, thin history, or a repo with poor structure can leave edges missing. That is why Repowise falls back instead of pretending certainty. get_answer is the one-call RAG path when the wiki has the answer. search_codebase is there when confidence is low. get_overview gives the architecture map when the agent is disoriented. Freshness and confidence scoring are there so the system can say “this answer is probably stale” instead of smiling through it.
That honesty matters more than it sounds. A graph-aware server should not try to replace search entirely. It should make search less repetitive and more targeted.
There is one more tradeoff worth saying out loud: graph context can be overkill for tiny edits. If you only need one string, the extra structure is just baggage. The trick is not to force graph everywhere. It is to make the graph available the moment the question stops being local.
Why Repowise ships seven task-shaped tools instead of one generic reader
The easiest mistake to make in MCP is to build a universal reader and call it intelligence. That tends to produce a server that can fetch text but cannot distinguish between “show me this file” and “tell me what breaks if I change this function.” Those are different jobs, so they deserve different tools.
Repowise ships seven task-shaped primitives because agents do not actually ask one generic question. They ask for overview, context, risk, why, dead code, and an answer with citations. Those are separate workflows, and the tools are aligned to them.
The architecture also starts to matter beyond one repository. repowise init . on a parent directory indexes every git repo underneath, then builds cross-repo intelligence: co-change pairs, API contract extraction for HTTP/gRPC/message topics, package dependency mapping, and federated MCP queries across repo='backend' or repo='all'. That is the natural extension of graph-aware mcp. Once the question spans repos, a file reader becomes even less useful.
The benchmark numbers are the proof that the shape is right: 36% cheaper, 49% fewer tool calls, 89% fewer files read, 19% faster wall time, and parity answer quality on SWE-QA. The token-efficiency result says the same thing more bluntly: 2,391 tokens per commit versus 64,039 naive and 14,888 from git diff.
If you care about the implementation details, the other reason this works is that the server is not just one source of truth. It combines graph intelligence, git intelligence, documentation intelligence, and decision intelligence, then keeps the agent on the shortest path through them. That is what makes the system feel like a codebase memory instead of a file browser.
FAQ
What is a graph aware MCP server?
A graph aware MCP server is an MCP server that returns structured codebase context around a target, not just file text. In practice that means symbols, callers, callees, ownership, freshness, docs, and related risk signals in one response.
How is a graph aware MCP server different from a file reader MCP?
A file reader MCP optimizes text retrieval. A graph aware MCP server optimizes neighborhood retrieval. The first tells you where a string appears; the second tells you how the code around that string behaves and who depends on it.
Does graph aware MCP reduce token usage for coding agents?
Yes. On the pallets/flask token-efficiency benchmark, Repowise averaged 2,391 tokens per commit versus 64,039 for a naive loop and 14,888 for git diff. That works out to 209× mean savings versus naive and 41.7× versus git diff.
When should I use grep instead of get_context in an MCP server?
Use grep for trivial lookup, config-only edits, and single-file scripts where the question is literally “where is this string?” Use get_context when the question is about callers, dependents, ownership, blast radius, or anything that could affect more than one file.
What happens when the graph is incomplete or confidence is low?
Repowise falls back to get_answer, search_codebase, or get_overview, and it uses freshness and confidence scoring to avoid pretending stale context is current. That matters because graph-aware context should reduce wrong turns, not hide uncertainty.


