Security review on a Python monolith with 19 hotspots
The first useful move in a Python monolith security review codebase pass is not “scan everything.” It is to find the 19 hotspots that actually concentrate risk, then review the paths around them once, in order, without making the agent read the same Python files twice.
That sounds obvious until you are the person with a release window and a repo full of auth middleware, request parsing, serializers, admin endpoints, and shared utility modules that all look vaguely implicated. The wrong starting point is the whole repo. The right starting point is the hotspot-driven review.
19 hotspots were enough to define the review surface
In this case, the repo was a Python monolith with enough surface area to make a blanket security review codebase pass feel responsible and still be mostly theater. The interesting part was not the number of files. It was the concentration of churn, complexity, and dependency centrality in a small set of places.
We started by ranking code that sat at the intersection of change frequency, structural complexity, and how many other modules depended on it. That collapsed the review surface to 19 hotspots. Not 19 files because they were “important,” but 19 because they kept showing up as the places where risk accumulated.
That matters. A pre-release security review is not a census. It is a search for the paths where bad assumptions can spread.
The 19 hotspots also gave us a way to talk about the repo without pretending every package deserved equal attention. A monolith usually resists that kind of triage because everything feels connected. But the useful unit of work was smaller: the code that was both touched often and structurally central. hotspot ranking is the right place to start, not the root directory.
 HOTSPOT REVIEW SURFACE
HOTSPOT REVIEW SURFACE
What surprised us was how much cleaner the review became once we admitted that the whole repo was the wrong starting point. We got this wrong initially: we began by asking for broad file lists, and the agent dutifully re-read the same modules in slightly different orders. That produced the comforting illusion of coverage and the practical reality of duplicate reads.
The hotspot-driven review fixed that by making the review surface explicit.
The Python paths that kept showing up in every pass
The repeated paths were not random. They clustered around a familiar set of Python security surfaces:
- auth middleware
- request parsing
- serialization and deserialization
- admin endpoints
- shared utility modules
Those are the places where a Python file can look harmless in isolation and still be the thing every other module trusts.
The review path that worked was simple enough to write down and strict enough to follow:
- Identify the entry points.
- Inspect the callers.
- Inspect the callees.
- Inspect the dependent modules.
- Stop when the context is sufficient to answer the security question.
That order matters because it prevents the same files from being pulled into multiple agent passes under different excuses. The point is not to read less. It is to read once, with graph context attached.
This is where the PreToolUse hook behavior paid for itself. Grep and Glob were not treated as blind search primitives. They were intercepted and enriched with the top related files from the local graph — symbols, importers, and uses — before the agent spent another pass rediscovering them. That is the difference between “searching the repo” and actually tracking the same paths twice? You stop doing it.
graph context is doing a lot of work here, because the context is not decorative. It tells you whether a symbol is an entry point, a leaf, or a shared dependency that will appear in every review pass until you pin it down.
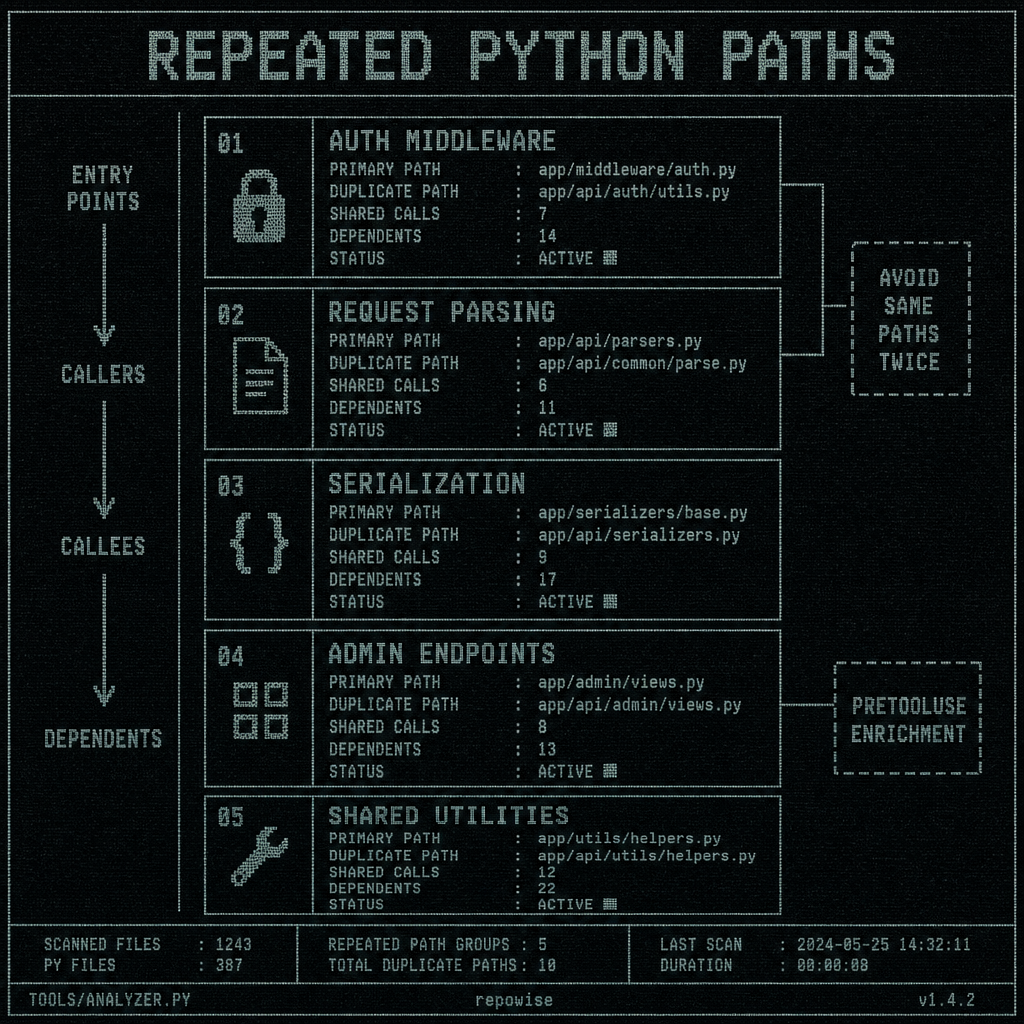 REPEATED PYTHON PATHS
REPEATED PYTHON PATHS
The useful thing about the graph is that it lets the agent see the review path instead of reconstructing it from scratch each time. That is why the same Python code no longer needs to be read twice by humans or agents.
Ownership gaps slowed the audit more than the code did
The technical risk was real, but the bottleneck was human. A hotspot with strong ownership is annoying. A hotspot with weak ownership is where a security review codebase pass starts bleeding time.
We looked at ownership %, bus factor, co-change partners, and who would actually review a change without hand-waving. The pattern was consistent: the deeper the hotspot sat in shared infrastructure, the more likely it was to have fuzzy accountability. That is not an org chart issue. It is a security issue.
If a hotspot has no clear owner, three things happen:
- The review slows down because nobody wants to be the final authority.
- The agent keeps widening the search because it cannot infer reviewer intent.
- The same files get re-read from different angles because the question was never bounded.
That is why ownership gaps belong in the first pass, not the last one. A file with no owner is not “just missing metadata.” It is a review risk signal.
We found it useful to think in terms of reviewers, not just owners. Ownership % tells you who is likely responsible. Reviewers tell you who can actually validate the security implications without a week of archaeology. When those two diverge too much, the hotspot is telling you to stop pretending the audit is purely technical. ownership gaps is the thing to fix before you ask for deeper scrutiny.
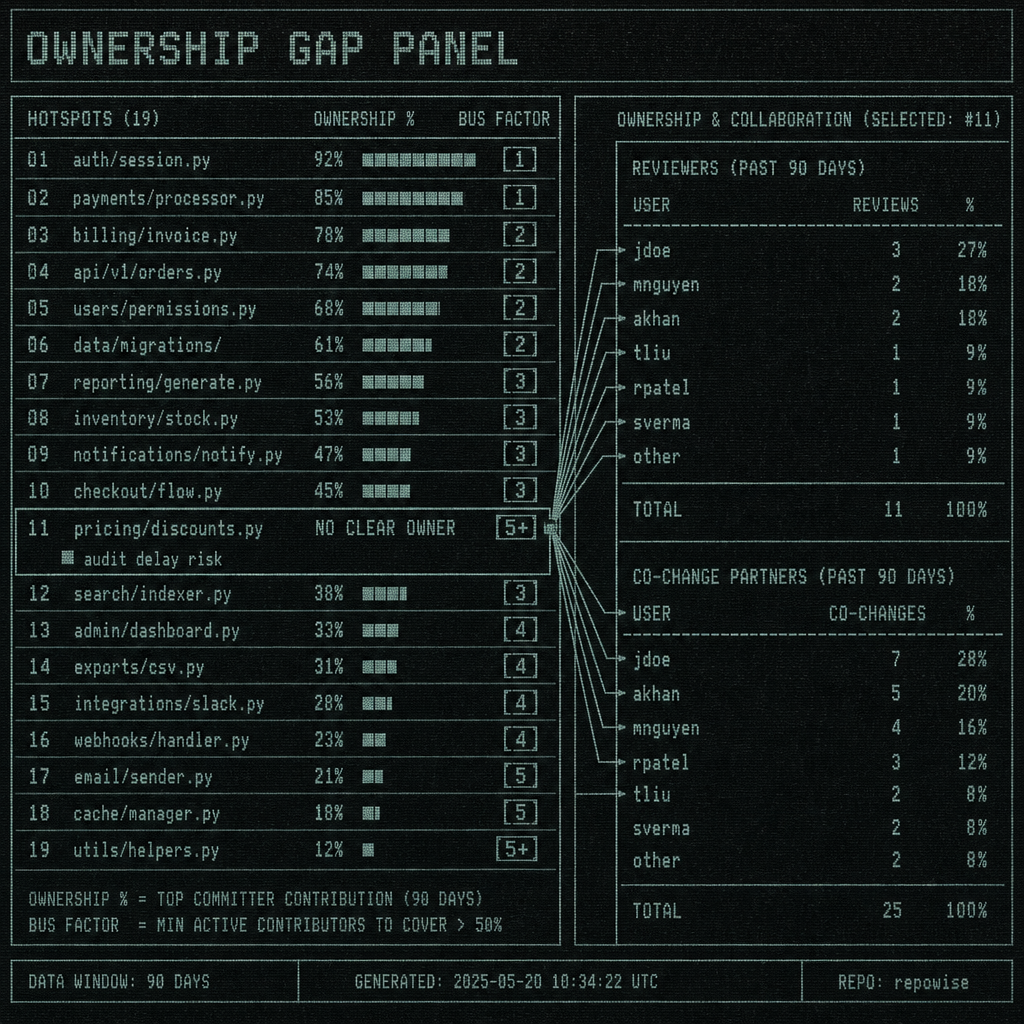 OWNERSHIP GAP PANEL
OWNERSHIP GAP PANEL
The non-obvious tradeoff: a strict hotspot-driven review can feel slower to managers who expect a broad sweep. It is slower only if you count “more files read” as progress. In practice, it gets you to the right humans sooner, which is what actually unblocks the audit.
Turn a security review into a bounded search problem
The playbook is boring in the best way.
Start with get_overview to get the architecture summary, module map, entry points, git health, and communities. That tells you where the monolith actually has seams. Then use get_risk to rank the hotspots by risk score, dependents, co-change partners, reviewer coverage, and test gaps. Then use get_context on the top 19 and stop when the confidence threshold for stopping is high enough to answer the review question.
That is the whole operating model: a bounded search problem, not an open-ended expedition.
The reason this works in a Python monolith is that security review codebase work rarely needs total recall. It needs enough context to answer questions like:
- Does this auth path trust input too early?
- Which dependent modules would amplify a bad change?
- Is the reviewer assignment actually credible?
- Are we looking at a real hotspot or just a noisy file?
get_overview, get_risk, and get_context map well to those questions because they are shaped around review work, not around generic search. risk scoring is what keeps the ranking honest; reviewing a file with full context is what keeps the agent from re-reading the same Python file as if it were new information.
A practical stopping rule helps. If the hotspot has a clear owner, a clear dependent set, and the relevant entry points/callers/callees all line up with the security question, stop. If any of those are missing, widen the scope deliberately rather than letting the agent keep wandering.
Before and after looks like this:
| Approach | What happens | Duplicate reads | Assignment speed |
|---|---|---|---|
| Naive repo-wide scan | Reads broad file sets, then re-reads the same Python modules through different prompts | High | Slow |
| Hotspot-driven review | Starts at ranked hotspots, follows entry points/callers/callees/dependents, stops at confidence threshold | Low | Fast |
The important part is not that the second row reads fewer files. It is that it reads fewer files twice.
Worked example: the review path for one risky Python hotspot
Here is a compact example from the audit pattern.
| Hotspot | Owner status | Risk signal | First file to inspect | Next related file | Stop condition |
|---|---|---|---|---|---|
app/auth/middleware.py | 42% ownership, two likely reviewers, one missing | High churn, central dependency, auth boundary | app/auth/middleware.py | app/api/views.py | Callers and callees explain the trust boundary; no new dependent path appears |
Step-by-step, the review path looked like this:
get_overviewto confirm the app entry points and the module map.get_riskonapp/auth/middleware.pyto confirm it is one of the top hotspots.get_contexton the hotspot withsource,callers,callees, andcommunityenabled.- Inspect the entry points first, then the callers that feed user input into the middleware.
- Inspect the callees that make the authorization decision.
- Confirm who reviews changes in that path.
- Decide whether the scope stays bounded or expands to adjacent modules.
That sequence avoided duplicate reads because the agent did not go back to the same file from a different angle. It had the graph context up front, so app/api/views.py showed up once, in the right place, instead of being rediscovered by a later grep.
The proof is not that one hotspot was easy. It is that the path was reusable. A staff engineer can hand this to an agent and know where the search starts, where it ends, and what would justify widening it.
This is also where a structured artifact helps. The OpenSSF security review materials are useful because they treat security review as a documented process, not a vague sense that “someone looked at it.” automatic file enrichment is the same instinct at the tool level: enrich the question before the second read happens.
When the risky code has no clear owner, split the review before you expand it
If a hotspot has no clear owner, or the dependency fan-out is so wide that the review path stops being bounded, the repo is not ready for targeted review. That is not failure. It is a triage result.
Use three criteria:
- Ownership clarity — is there a real reviewer who can sign off?
- Dependency shape — does the hotspot have a contained caller/callee set?
- Risk concentration — does the code still look like a hotspot after context, or just a noisy neighbor?
If the answer to any of those is no, do not keep pretending a surgical pass will work. Either assign ownership first or widen to a broader sweep that makes the missing context explicit.
That is the release or audit decision rule: targeted review when the hotspot is owned and bounded; broader sweep when it is not.
A Python monolith does not become safer because you inspected every file. It becomes safer when the 19 hotspots are understood, the ownership gaps are closed, and the review path is short enough that no one has an excuse to read the same code twice.
FAQ
How do you do a security review codebase pass on a Python monolith without scanning every file?
Start with ranked hotspots, not the repo root. Use a bounded path: entry points, callers, callees, and dependents around the risk-bearing files. Stop when the confidence threshold for the review question is high enough.
What is a hotspot-driven review in a security audit?
It is a review that treats the highest-risk files or symbols as the unit of work. The ranking usually comes from churn, complexity, dependency centrality, ownership gaps, and the size of the blast radius.
What should I do when a risky Python file has no clear owner?
Treat that as a security issue, not a process note. Assign a reviewer before widening the scan, or declare the hotspot ready only for a broader sweep if the ownership gap cannot be closed quickly.
How do I tell whether a repository is ready for a targeted security review or needs a broader sweep?
If the hotspot set is small, ownership is clear, and the entry points/callers/callees form a bounded path, it is ready for targeted review. If ownership is missing or the dependency fan-out keeps growing, switch to a broader sweep first.
What files should I inspect first in a Python security review?
Start with auth middleware, request parsing, serialization, admin endpoints, and shared utility modules that sit on critical paths. Then inspect the callers and callees around those files before widening the scope.


