Claude Code vs Cursor on a Python import cycle
A small Python import cycle can turn a clean refactor into a dependency-shape exercise. The interesting part of claude code vs cursor is not which one writes prettier edits; it is which one notices that the file you opened is only half the graph, and that breaking the cycle without changing behavior means moving a boundary, not just moving a line.
The same Python import-cycle refactor, run through Claude Code and Cursor
The task was simple to state and annoying to execute: break an import cycle in Python without changing behavior. The code had two modules that had grown toward each other until the imports started feeding back on themselves. One module defined a type and a helper, the other used both, and then the first module started importing a function back from the second module because “it was already there.”
That is the kind of refactor where local correctness is cheap and global correctness is expensive. A human looks at the package and asks: which module owns the shared type, which one owns orchestration, and which import edge is actually backwards? An agent that only sees the open file can produce a neat edit that still leaves the cycle intact.
Here is the kind of shape we were dealing with:
# before.py
# app/models.py
from app.services import format_user
class User:
def __init__(self, name: str):
self.name = name
def label(self) -> str:
return format_user(self)
# app/services.py
from app.models import User
def format_user(user: User) -> str:
return f"User<{user.name}>"
That looks harmless until models.py imports services.py, and services.py imports models.py. The fix is not to “make the import lazy” unless you enjoy hidden coupling. The fix is usually to introduce a third module that owns the shared boundary and leaves the direction of dependency obvious.
Python’s own docs are blunt about circular imports: modules are executed at import time, so partially initialized modules are a real thing, not a theoretical one. circular import patterns This is why the comparison here is about dependency topology, not editor ergonomics.
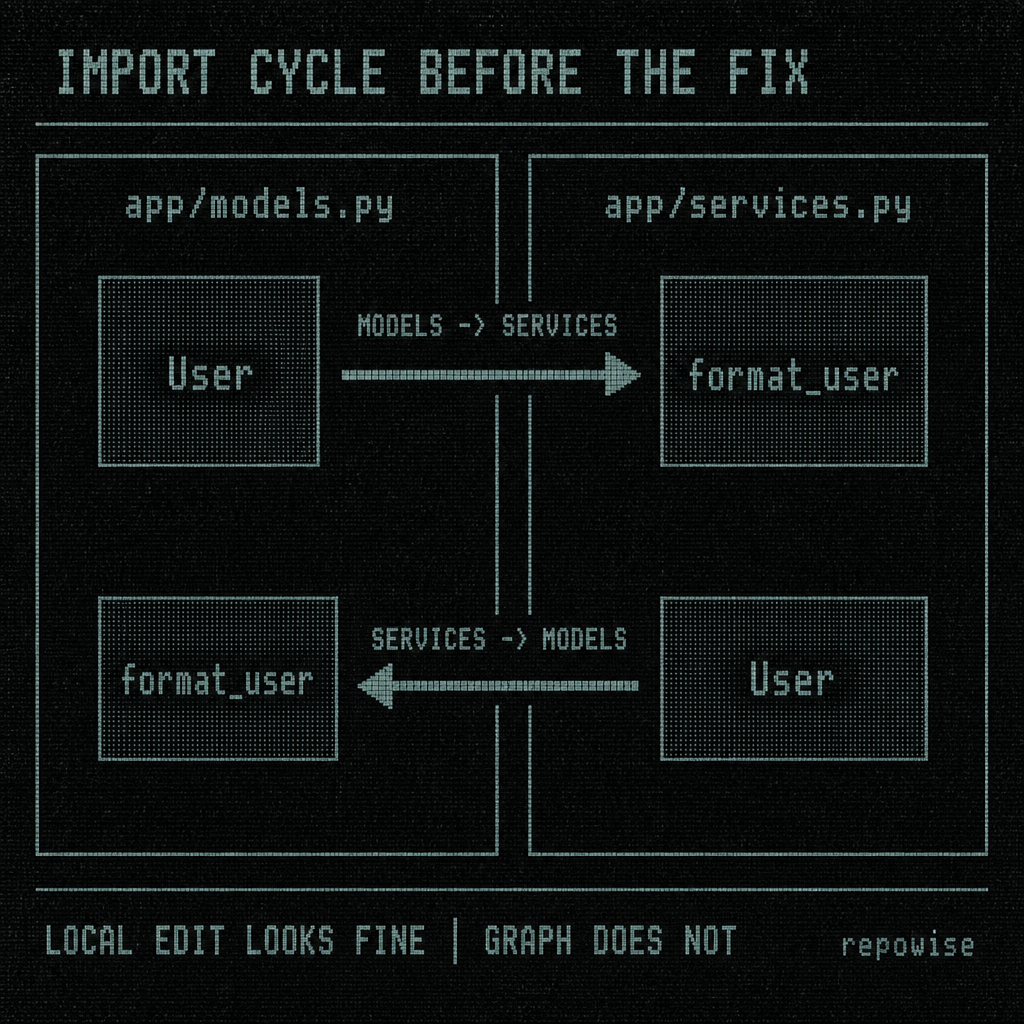 IMPORT CYCLE BEFORE THE FIX
IMPORT CYCLE BEFORE THE FIX
The prompt we used, and the one sentence that changed the run
The prompt was nearly identical for both tools. The only part that made a visible difference was the sentence that forced graph inspection before editing.
You are refactoring a Python codebase.
Goal: break the import cycle between app.models and app.services without changing behavior.
Current behavior:
- User.label() still returns the same string
- format_user() still formats the same object
- public imports should stay stable if possible
Before editing, list:
1) the files that import app.models
2) the files that import app.services
3) the symbols that create the cycle
Then propose the smallest safe refactor.
Important: do not edit until you have traced importers and callees across the package.
Show the dependency shape first, then make the change.
The sentence that changed the run was the last one: “Do not edit until you have traced importers and callees across the package.”
What we did not say mattered just as much. We did not say “use a helper,” “move code into utils,” or “prefer dataclasses.” We also did not tell either tool which module should own the boundary. That omission is where the first run failed in different ways.
 PROMPT THAT FORCES GRAPH AWARENESS
PROMPT THAT FORCES GRAPH AWARENESS
What Claude Code did when the dependency graph mattered
Claude Code was the one that most quickly reconstructed the cycle from the prompt and the visible files. It did not just patch the import line. It first named the two modules, then inferred that models.py was trying to consume presentation logic from services.py while services.py was already depending on the model type. That was the right mental model.
The first mistake was subtler than a wrong import. Claude Code assumed the shared behavior belonged in the service layer, so it proposed moving the formatter into services.py and making models.py call through a thin adapter. That would have “worked,” but it would have preserved the coupling in a less obvious form. It was a classic module-ownership error: treating the module that was easiest to edit as the module that should own the abstraction.
The useful part is that it recognized the dependency shape early. It understood that the fix had to sit above both modules, not inside one of them. After a follow-up prompt that asked it to keep the public behavior and move shared pieces into a third module, it produced the right split: the shared type stayed where it belonged, the formatter moved to a boundary module, and the cycle disappeared.
So the final edit was correct, but only after a correction prompt. That is still a good result. It means Claude Code was more willing to reason across the whole graph, even if it initially overreached on ownership.
Tools like Claude Code, Cursor, and Repowise all expose this tension differently; the difference is whether the agent starts with the graph or with the open buffer. repository graph context
Where Cursor stayed local and missed the cycle
Cursor’s first pass was faster and more locally competent. It focused on the file that was open, improved the function signature, and made the code look cleaner in isolation. If you only read that file, it was a decent edit.
But the first attempt stayed trapped in the visible symbol. Cursor changed the implementation of format_user() and tightened a type annotation, then stopped. It did not go hunting for upstream importers. The missed edge was the import from models.py back into services.py, which meant the cycle survived even though the file on screen looked cleaner.
That is the failure mode to expect from Cursor on this task shape: strong local edits, weak default pressure to inspect the package graph. If you do not force it to enumerate importers, it will often optimize the current file instead of the dependency boundary.
It recovered on the second prompt once we spelled out the cycle explicitly and asked it to inspect the importing modules first. At that point it could do the same refactor Claude Code had eventually done. The difference was not capability so much as steering cost. Cursor needed the graph made explicit. Claude Code was likelier to reconstruct it on its own.
 LOCAL EDIT VS GRAPH VIEW
LOCAL EDIT VS GRAPH VIEW
A worked example of the import cycle, before and after the fix
Here is the minimal version of the refactor boundary.
# before
# app/models.py
from app.services import format_user
class User:
def __init__(self, name: str):
self.name = name
def label(self) -> str:
return format_user(self)
# app/services.py
from app.models import User
def format_user(user: User) -> str:
return f"User<{user.name}>"
After the refactor, the shared shape moved into a third module:
# after
# app/types.py
from dataclasses import dataclass
@dataclass
class User:
name: str
# app/formatting.py
from app.types import User
def format_user(user: User) -> str:
return f"User<{user.name}>"
# app/models.py
from app.types import User
class UserModel(User):
def label(self) -> str:
return f"User<{self.name}>"
There are many valid ways to break the cycle. The important part is the boundary: one module owns the data shape, another owns formatting, and neither has to import the other to do its job. That preserves behavior because the string output stays the same, while the import graph becomes acyclic.
This is also why the best refactor answer is rarely “move code to utils.” Shared modules work only when they represent an actual abstraction, not a junk drawer. A graph-aware agent is more likely to ask which side owns the concept, not just which file has fewer lines.
If you want to see this kind of boundary before an agent starts editing, a codebase graph makes the cycle obvious in a way grep never will. Python module boundaries how we use AI coding agents day to day
Which agent I would trust for the next Python import rewrite
For this specific task shape, I would trust Claude Code first. Not because it is always right, and not because Cursor is weak. I would trust Claude Code because it is more likely to reason across the whole dependency shape without being explicitly told where the cycle lives.
Cursor is still the better choice when the refactor is mostly local and you want fast, ergonomic edits in one file. It is very good at staying close to the code you are touching. That becomes a liability when the bug is not in the code but in the edge between modules.
Here is the practical rule I would reuse:
- Ask the agent to list importers and callees before it edits anything.
- Force it to name the cycle in plain English.
- Make it state which module owns the shared boundary.
- If it proposes a workaround inside one file, assume the graph is still wrong.
The failure modes are predictable:
| Tool | First move | Missed edge | Correction needed | Final outcome |
|---|---|---|---|---|
| Claude Code | Reconstructed the cycle and proposed a split | Module ownership, at first | Follow-up prompt to keep the boundary clean | Correct after one correction |
| Cursor | Edited the visible file well | Upstream importer back into the open module | Second prompt to inspect importers | Correct after explicit graph prompt |
The useful comparison in claude code vs cursor is not “which one is smarter.” It is which one is easier to steer when the refactor depends on seeing the graph, not just the code. For teams doing this daily, that distinction matters more than raw autocomplete quality.
FAQ
Is Claude Code or Cursor better for Python circular imports?
For Python circular imports, Claude Code is usually easier to trust on the first pass because it is more likely to reason about the dependency graph, not just the open file. Cursor can absolutely fix the problem, but it often needs the cycle spelled out and the importers enumerated before it will leave the local view.
How do you prompt Claude Code to fix an import cycle?
Tell it to list importers, callees, and the symbols that form the cycle before editing. The key sentence is: “Do not edit until you have traced importers and callees across the package.” That usually changes the behavior more than asking for a “better refactor.”
Why does Cursor miss cross-file dependencies in a Python refactor?
Cursor is strong at local edits, so it tends to optimize the file you opened. If the bug depends on an upstream importer or a downstream callee, it may not visit that edge unless the prompt forces it to inspect the package graph. That is why it can leave the cycle intact while making the current file look cleaner.
What is the best way to break a circular import in Python?
Move the shared concept into a third module that both sides can depend on without depending on each other. Usually that means separating data shape, formatting, or orchestration into different modules so the import direction becomes one-way. Avoid “lazy import” unless you have a very specific reason and understand the tradeoff.
Can a codebase graph help with import cycles?
Yes. A codebase graph makes the cycle visible before an agent starts editing, which is often the difference between a correct boundary split and a local patch that preserves the loop. That is the kind of context a graph-aware workflow is meant to surface.
