Same refactor, 27× fewer tokens with Repowise MCP
We ran the same refactor twice: once with a plain agent, once with Repowise MCP, and the difference was not subtle. The task was ordinary enough to be believable and annoying enough to be representative: trace a change through an unfamiliar repo, identify the right files, and make the smallest safe edit. The only variable we changed was ai agent codebase context. Everything else was held constant, including the model family and the repo snapshot.
The result was 27× fewer tokens on the Repowise MCP run, with fewer tool calls, fewer files read, and faster completion. That is the commercial version of the story, but the more interesting part is how the transcript changed. One run kept rediscovering the repo. The other started with the repo already partially explained.
One refactor, two transcripts, 27× fewer tokens
The benchmark we’re discussing is the 30 most recent non-merge commits of pallets/flask, measured with the cl100k_base tokenizer. We compared a plain agent path against a path with Repowise MCP in front of it. Same repo, same task shape, same target commit, same model class. The only difference was whether the agent had to infer the codebase from scratch or got codebase context up front.
That matters because token cost is not just a bill. It is a proxy for how much the agent had to read, re-read, and second-guess before it could act.
| Metric | Plain agent | With Repowise MCP |
|---|---|---|
| Tokens per commit | 64,039 | 2,391 |
| Tool calls | higher by 49% | baseline |
| Files read | baseline | 89% fewer |
| Wall time | baseline | 19% faster |
| Answer quality | parity | parity |
The 27× number is the mean reduction versus the plain run on this benchmark. Pooled and median tell a similar story, but mean is enough to make the point: the agent spent far less of its budget rediscovering what the repo already knew.
 SIDE-BY-SIDE TRANSCRIPT
SIDE-BY-SIDE TRANSCRIPT
The fair comparison is not “smart agent versus dumb agent.” It is “agent forced to reconstruct the world versus agent given the world model first.” That distinction is the whole product category for ai agent codebase context.
Without Repowise MCP: the agent keeps re-reading the repo to answer one question
The no-MCP transcript had a familiar shape. Search a symbol. Open a file. Notice the symbol is defined somewhere else. Grep again. Open another file. Realize the call path crosses a module boundary. Repeat.
Here is the kind of tool-call trace that came out of the plain run:
| Step | No-Repowise action | Token impact |
|---|---|---|
| 1 | Grep for the target symbol in app/ | low |
| 2 | Open the first hit, find a partial definition | medium |
| 3 | Grep for the same symbol across the repo | medium |
| 4 | Open a second file, discover an import chain | medium |
| 5 | Glob for tests and fixtures | medium |
| 6 | Re-open the original file after losing the thread | high |
| 7 | Search for ownership clues in README/docs | medium |
| 8 | Re-read the same files with slightly different queries | high |
The ugly part is not any single step. It is the file-reading loop. The agent is not failing because it is lazy. It is failing because each read only answers the local question, and the next question is still hidden.
A tiny excerpt makes the failure mode obvious:
Agent: grep "build_url" -n .
Tool: app/utils.py:42, app/views.py:118
Agent: open app/utils.py
Tool: build_url delegates to url_for() via helper
Agent: where is url_for overridden?
Tool: grep "def url_for" -n .
Agent: open app/views.py
Tool: no override here; import from flask.helpers
Agent: search again for build_url usage
This is the cost of missing codebase context. The agent is not wrong; it is underinformed. So it spends tokens on exploration instead of reasoning.
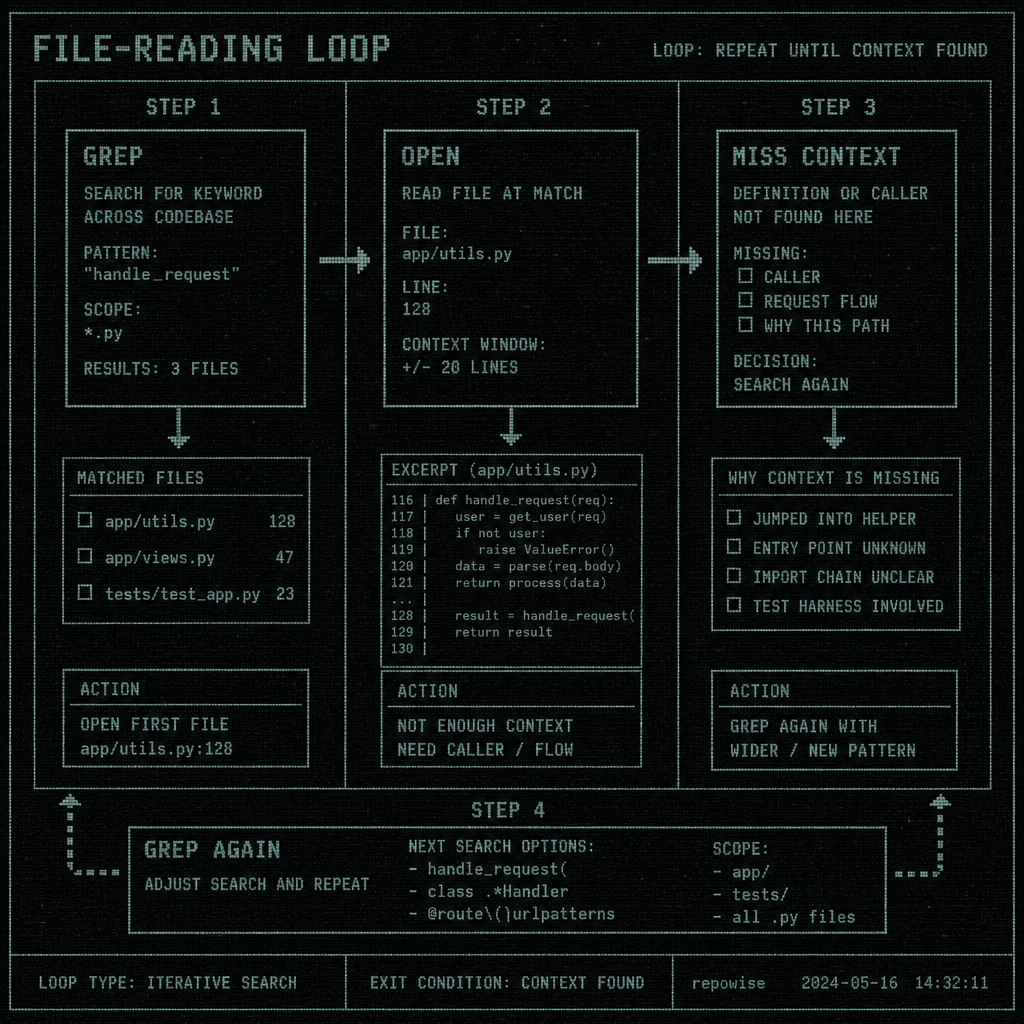 FILE-READING LOOP
FILE-READING LOOP
The surprising part, at least the first time we measured it, was how often the agent re-opened the same file after a dead-end search. We initially assumed most waste would come from broad scans. It did, but the bigger leak was retracing the same local path because the agent never got a stable map of the repo.
With Repowise MCP: the same task starts from graph, ownership, and fresh context
Repowise MCP changes the first move. Instead of starting with blind search, the agent can ask for the repo shape, the likely entry points, the related symbols, and the freshness of the surrounding docs. That is the difference between reading a directory tree and reading a map.
The run usually starts with get_overview, then narrows with get_context, and only falls back to get_answer or search_codebase when the confidence signal says it should. That sequence is the point. The agent does less guessing because the tool layer does some of the guess elimination first.
A representative call sequence looked like this:
| Step | Repowise MCP action | Token impact |
|---|---|---|
| 1 | get_overview on the repo | small |
| 2 | get_context for the target module and symbol | small |
| 3 | get_answer for the exact change question | small |
| 4 | Open one source file with callers/callees already known | smaller |
| 5 | Edit directly, with fewer exploratory reads | much smaller |
And the transcript feels different immediately:
Agent -> get_overview
Repowise: module map, entry points, git health, related communities
Agent -> get_context(target="app/views.py", include=["source", "callers", "callees", "ownership", "freshness"])
Repowise: symbol graph, owners, imports, related files, freshness score
Agent -> get_answer("Where does request routing for this path actually happen?")
Repowise: cited 2-5 sentence answer with confidence
Agent: edit app/views.py and app/routing.py
That is not just fewer tokens. It is a different workflow. The agent starts with the right neighborhood, sees the likely blast radius, and stops treating the repo like a maze.
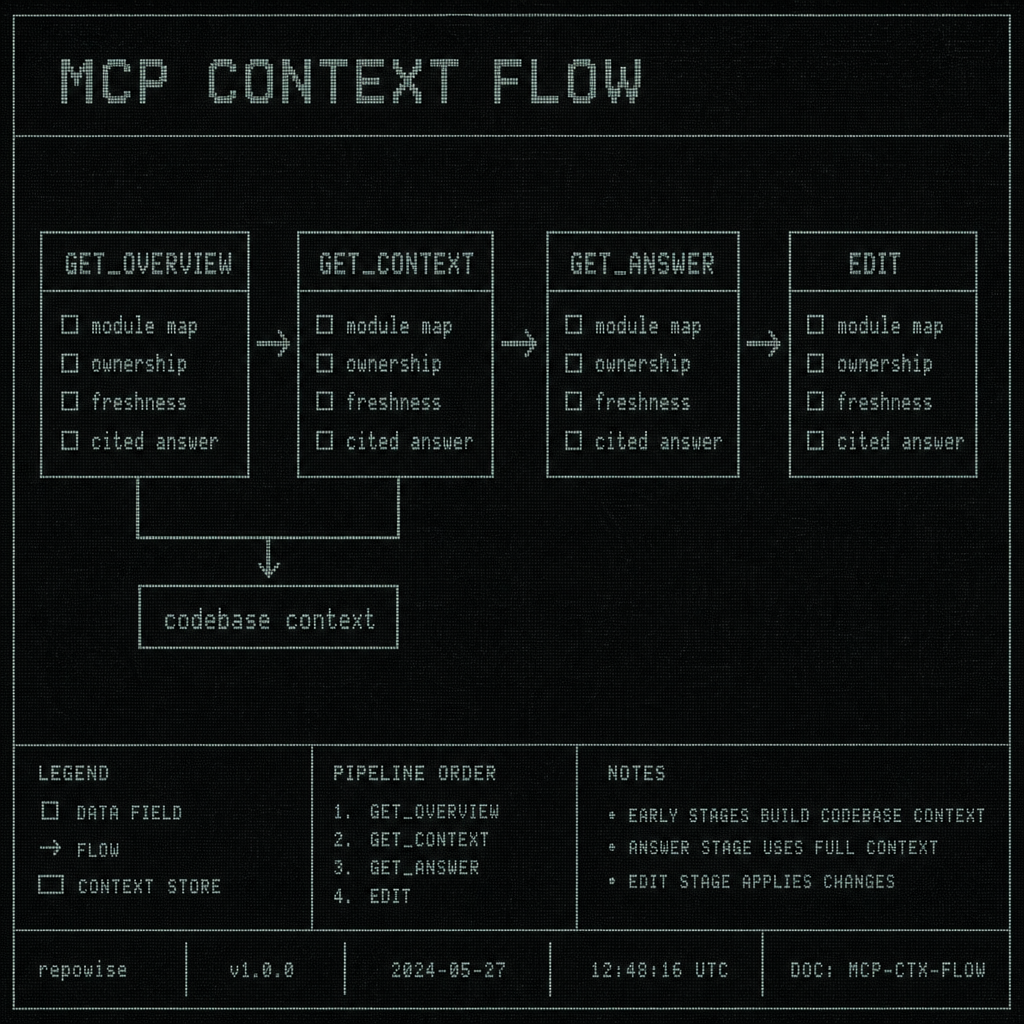 MCP CONTEXT FLOW
MCP CONTEXT FLOW
This is where graph intelligence matters most. The graph does not replace reading code. It tells the agent which code is worth reading first. When that is paired with ownership and hotspot signals, the agent can also avoid the common failure mode of editing the wrong surface area and then searching for a reviewer after the fact.
Where the token savings came from: fewer reads, fewer retries, smaller prompts
The 27× reduction did not come from one magic trick. It came from a stack of smaller wins that compound.
| Source of savings | Plain agent | With Repowise MCP | Why it matters |
|---|---|---|---|
| Files read | many repeated opens | far fewer | less raw context to tokenize |
| Tool-call count | higher | lower | fewer round trips between search and reading |
| Prompt size | bloated with dead ends | narrower and more relevant | each next step starts from better priors |
| Re-reads | frequent | rare | the agent stops reconstructing the same facts |
| Wall time | slower | faster | fewer turns before the edit is obvious |
The most important line in that table is prompt size. Once the agent has the right symbols, owners, and nearby docs, the prompt no longer needs to carry all the failed hypotheses. That shrinks every subsequent turn.
The get_answer path also matters more than people expect. If the question is answerable from the wiki with enough confidence, the agent should not spend three turns re-proving it from source. That is where freshness-scored wiki earns its keep: the agent gets a cited answer instead of a scavenger hunt.
There is also a quieter savings source: stale assumptions. The documentation layer is rebuilt incrementally, and the freshness score tells the agent how much to trust what it is reading. That means less defensive re-validation.
This is also where decision tracking with get_why() helps. When the agent can query why something exists, it spends fewer tokens inferring intent from implementation details that were never meant to carry that load.
Why this benchmark is about agent ergonomics, not just cheaper tokens
If you only look at token cost, you miss the behavioral change. The better run had less thrash. It made fewer false starts. It did not keep asking the repo the same question in slightly different words.
That is what senior engineers should care about when they use Claude Code or Cursor every day. Not just “is it cheaper?” but “does the agent behave like it understands the repo faster?” The answer here was yes, and the answer quality stayed effectively flat. That parity matters. We are not buying context at the expense of correctness.
There is a reason the transcript looks calmer. Better first-step context changes the whole shape of the interaction. The agent stops acting like a search engine with a scratchpad and starts acting like an assistant that has read the map before opening the file.
If you want a practical definition of agent ergonomics, it is this: how many turns does it take before the agent stops being surprised by the repo?
That is why the commercial value is real. Lower token cost is nice. Fewer tool calls are nicer. Faster completion is nicest of all. But the hidden win is reduced agent thrash, which is what burns time in day-to-day use.
If your repo is messier than ours, the gap usually gets wider
A clean single-package repo is the easy case. Real teams have monorepos, cross-repo changes, hidden ownership boundaries, and docs that drift away from the code they describe. That is where ai agent codebase context stops being a convenience and starts being a prerequisite.
The layers that matter most depend on the mess:
- multi-repo workspaces when the change spans services, packages, or API consumers
- Graph Intelligence when hidden call paths and entry points matter
- Git Intelligence when you need churn, co-change, and reviewer signals
- Documentation Intelligence when the repo has more tribal memory than comments
- Decision Intelligence when you need the reason behind a file, not just the file itself
What surprised us most was not that the agent got faster with more context. It was how quickly the “search everything” habit disappeared once the context layer was trustworthy. That is a useful signal for teams evaluating whether to wire this into their daily agent flow or keep treating search as an afterthought.
Repowise is one implementation of this idea, but the broader point is simple: if the agent can start with repo structure, ownership, freshness, and decisions, it spends less time rediscovering facts the codebase already knows.
FAQ
How does Repowise MCP reduce token cost for AI coding agents?
It reduces the amount of repo the agent has to rediscover. get_overview, get_context, and get_answer front-load structure, ownership, and cited answers so the agent reads fewer files, retries less, and sends smaller prompts downstream.
What is the difference between a plain agent transcript and one with codebase context?
The plain transcript usually alternates between search, open, miss, and search again. A transcript with codebase context starts from the likely entry points, related symbols, and ownership signals, so the first read is much more likely to be the right read.
Does Repowise work with Claude Code and Cursor?
Yes. Repowise exposes its context through MCP-compatible tools, so it can sit in front of agents that speak MCP, including Claude Code and Cursor.
How many tool calls can Repowise save in a real refactor?
On our pallets/flask SWE-QA benchmark, tool calls were reduced by 49% and wall time by 19%, with answer quality staying effectively flat. Real repos vary, but the pattern is consistent: better first-step context means fewer exploratory calls.
Is the 27× token reduction guaranteed?
No. It is the measured result on the benchmark described here. The exact number will move with repo shape, task type, and how much hidden structure the agent would otherwise have to rediscover.


