Audit a legacy monolith before acquisition with graph, history, wiki, ADRs
A pre-acquisition legacy code audit usually starts with the wrong artifact: a grep result, a spreadsheet, or a heroic read-through by someone who is already tired. That is how you miss the questions that actually decide a deal. The useful questions are simpler and harsher: what breaks if we touch this, who owns it, and what was intentionally decided versus accidentally accumulated? If you want to audit legacy code before acquisition, start with the repository’s own evidence, not with confidence.
A pre-acquisition audit needs evidence, not a file search
A pre-acquisition legacy code audit is not a scavenger hunt for suspicious strings. It is an attempt to reduce uncertainty before you sign, freeze, or delete.
Grep is fine for finding a symbol. It is bad at answering why a feature exists, whether a module is on a critical path, or whether a file is old because it is stable or old because nobody knows how to change it. It misses transitive dependencies and hidden entry points. It also misses the social layer: who still touches this, who stopped touching it, and which parts of the system have become institutional memory with no owner.
That is why the diligence questions collapse into three buckets:
- What breaks if we change it?
- Who actually owns it?
- What was intentionally decided?
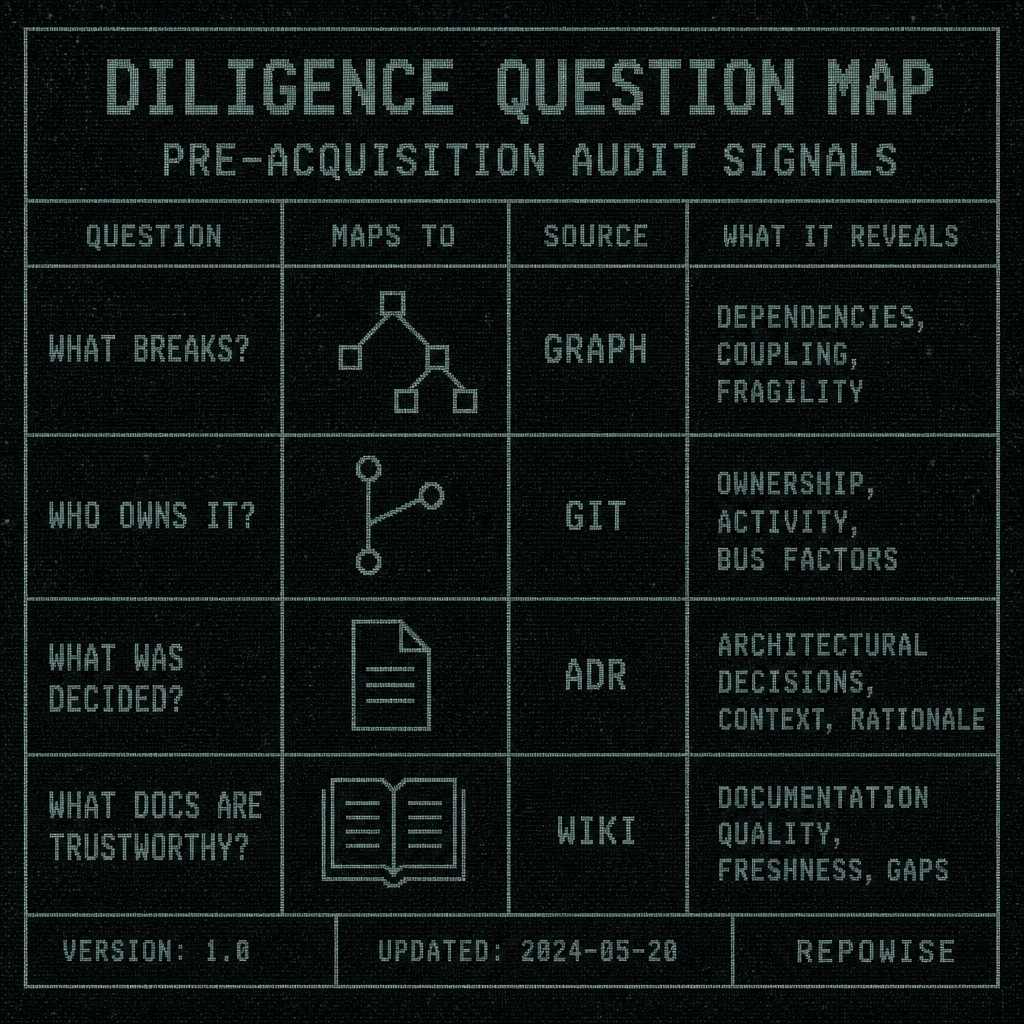
Those map cleanly to four evidence layers: graph, history, wiki, and ADRs. The point is not that these layers are exhaustive. The point is that they are enough to make a buy/freeze/rewrite decision without pretending the codebase is a mystery novel.
Here is the practical framing I use:
| diligence question | layer used | signal to look for | what decision it informs |
|---|---|---|---|
| What breaks if we touch this? | Graph intelligence | dependents, centrality, SCCs, execution flow | freeze, rewrite, or deeper review |
| Who owns it? | Git intelligence | ownership %, co-change pairs, bus factor | buy, staff, or escalate |
| What was intentionally decided? | Decision intelligence | ADRs, path-linked decisions, staleness | keep, replace, or verify |
| What should we trust in docs? | Documentation intelligence | freshness and confidence scores | trust, cross-check, or ignore |
If you want a contrast, NDepend’s legacy audit framing is metrics-first, which is useful in its own way. SourceCodeReviews frames audits around acquisition and merger diligence, which is closer to the actual business question. But the useful move is the same: stop treating the repo as raw material and start treating it as evidence.
the graph layer
 DILIGENCE QUESTION MAP
DILIGENCE QUESTION MAP
Read the tree-sitter dependency graph for hidden blast radius
The tree-sitter dependency graph is the first thing I want when I audit legacy code because it answers a question grep cannot: where does change propagate?
A file can be small and still be dangerous. The graph surfaces entry points, callers, callees, strongly connected components, and execution flow from entry points. That gives you blast radius from dependents and centrality, not from vibes.
The useful mental model is this: centrality is not just “important.” It is “if this shifts, how many unrelated things wobble?” Betweenness is often more revealing than size. A tiny adapter in the middle of a path can matter more than a giant module that nobody imports directly.
One example I keep seeing: a 140-line utility file that looks like glue. In the graph, it sits on the path between request entry points and three downstream service clusters. Its PageRank is high, its betweenness is higher, and it belongs to a strongly connected component that spans code nobody would call related in a directory listing. That file is not glue. It is a choke point with a friendly filename.
This is where the graph pays for itself during acquisition. You can ask:
- Which modules have many dependents?
- Which entry points reach the most code?
- Which SCCs suggest hidden coupling?
- Which “leaf” files are actually shared infrastructure?
If you want a single suspicious-module walkthrough, use the graph first. Suppose a module looks harmless. The graph says it has many dependents. Then you inspect history and find repeated fixes. Then the wiki page is stale. Then the ADR is missing or contradictory. At that point, the module is not “legacy.” It is unresolved.
 HIDDEN BLAST RADIUS
HIDDEN BLAST RADIUS
blast radius signals
Use git history to separate active risk from burial sites
Git history is where you stop confusing age with risk.
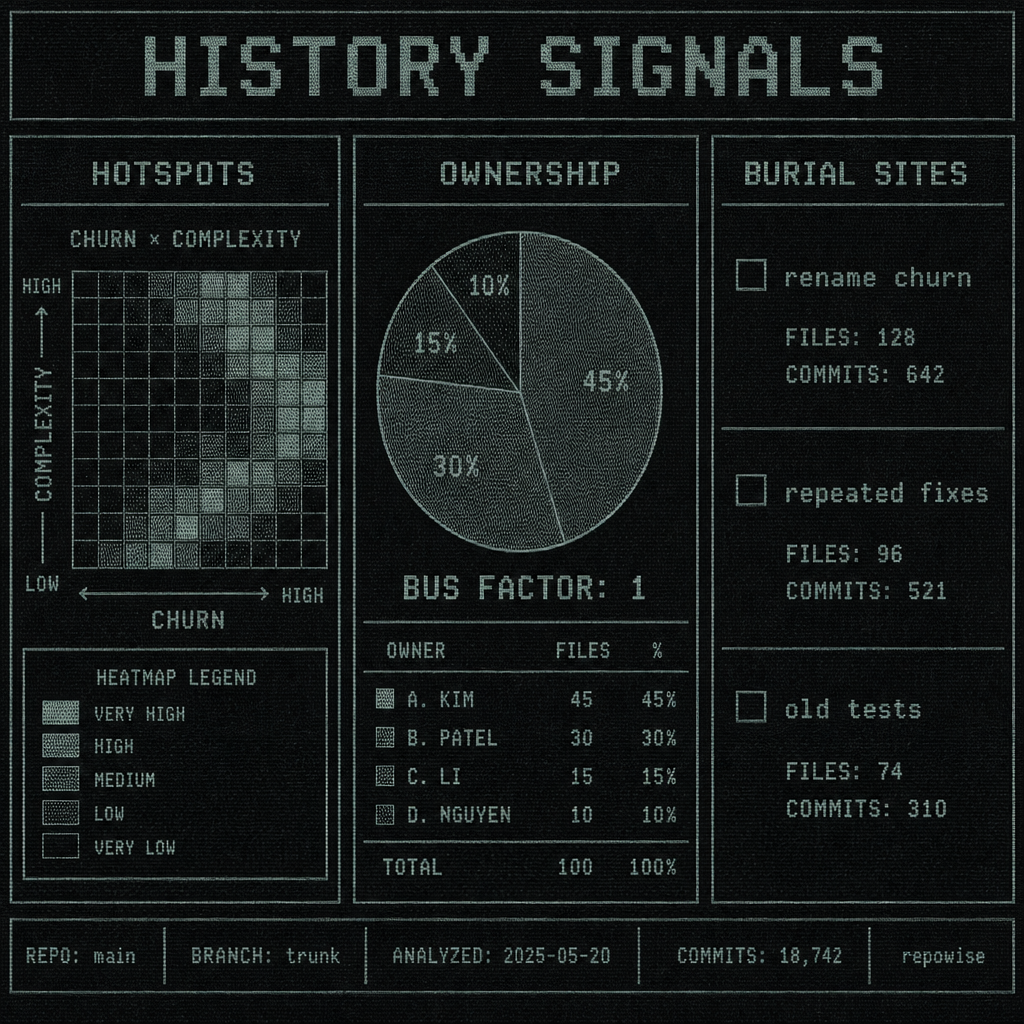
A file that has been untouched for 18 months may be perfectly fine. Or it may be a burial site: a place where bugs go to be patched, renamed, and forgotten. The difference shows up in churn × complexity, ownership concentration, bus factor, co-change pairs, and significant commit messages.
Hotspots from churn × complexity are the obvious starting point. A file that changes often and is already hard to understand deserves attention before acquisition because it is likely to absorb future cost. But ownership concentration matters just as much. If 90% of changes come from one person, your bus factor is not a theoretical risk metric. It is a staffing problem with a deadline.
The part people miss is repeated fixes. Files with rename churn, suspiciously old tests, or commits that say some version of “temporary,” “hotfix,” “revert,” or “work around” are often burial sites. They look quiet because they have been repeatedly stabilized. That is not the same thing as understood.
We got this wrong initially in one audit sequence: we over-weighted “recently changed” and under-weighted “repeatedly changed for the same reason.” The former is activity. The latter is unresolved risk. A file touched once this month may be stable. A file touched ten times over two years for the same edge case is telling you it has never been made boring.
A practical readout from git history should include:
- hotspots from churn × complexity
- ownership concentration and bus factor
- co-change partners
- significant commit messages
- suspiciously old tests near active code
 HISTORY SIGNALS
HISTORY SIGNALS
When the wiki is stale enough to be evidence, not truth
Documentation intelligence is useful only if it tells you how much not to trust the documentation.
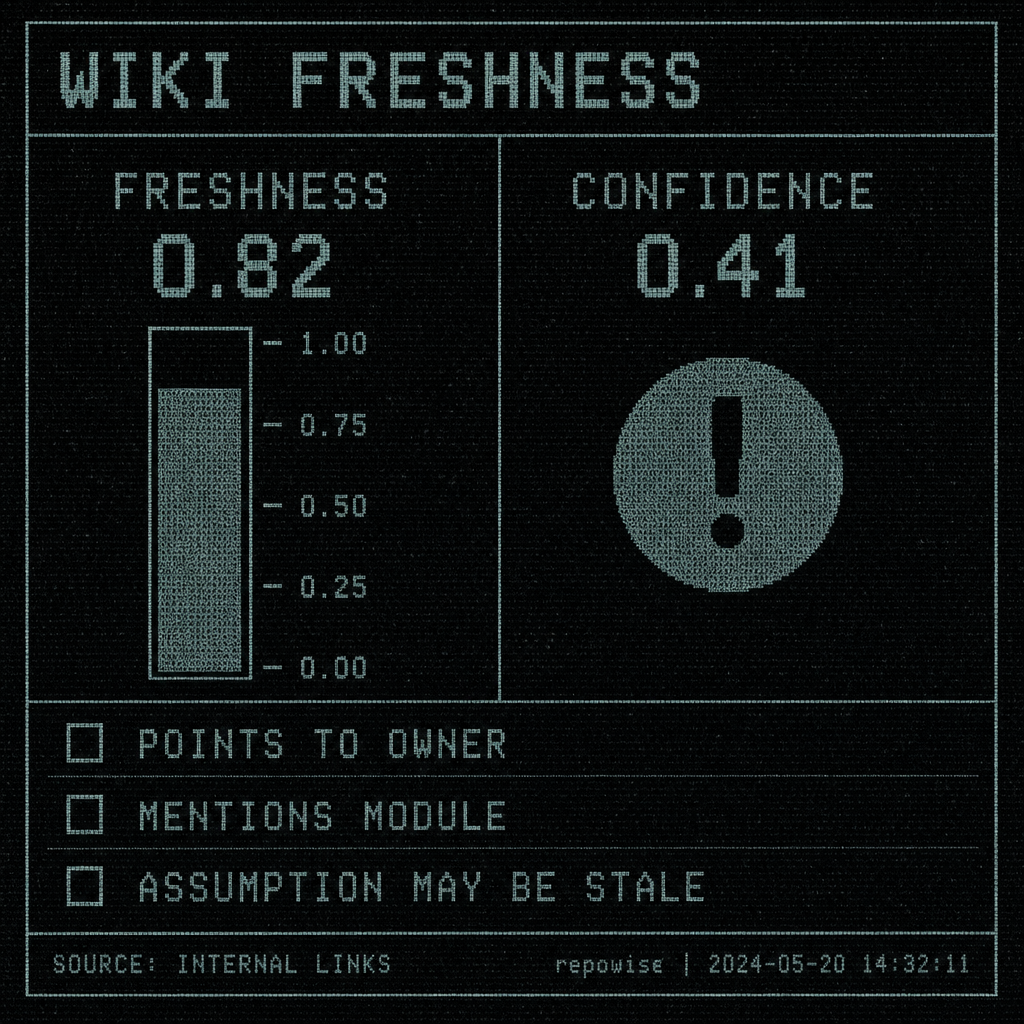
That is why wiki freshness scoring matters. Freshness and confidence are not the same thing. A page can be confident and stale, or fresh and uncertain, and those are different audit signals. Freshness tells you whether the page likely reflects the current system. Confidence tells you whether the model had enough evidence to write it in the first place.
For a pre-acquisition legacy code audit, stale pages are not useless. They are often the best evidence of historical assumptions. A stale page can still point to module names, owner names, migration plans, and decisions that were once central. What you should not do is treat it as a source of truth without cross-checking.
A simple rule works well:
- Trust a page when freshness is high and the page agrees with graph or git signals.
- Cross-check a page when freshness is medium or confidence is low.
- Ignore a page as factual evidence when it is stale and unsupported, but keep it as a lead for owners, modules, and old assumptions.
That last part matters. In diligence, a stale wiki page is often more valuable as a breadcrumb than as a fact sheet. It can tell you what the team believed when they last touched the system, which is exactly the kind of thing an acquirer needs to know.
 WIKI FRESHNESS
WIKI FRESHNESS
ADRs tell you what the team was protecting when they chose this shape
Architectural decision records are the only layer here that directly answers “why is the system shaped like this?”
That matters before purchase or rewrite because the worst legacy systems are often not badly built. They are built around decisions that were rational at the time and are now invisible. ADRs make those tradeoffs legible again.
The missing-ADR problem is underrated. If a codebase has no decision trail for its database choice, queueing model, auth boundary, or monolith split, you do not just lack history. You lack the ability to tell whether the current shape is deliberate or accidental. That is a real acquisition risk. It means a rewrite proposal can be based on aesthetics instead of constraints, and a freeze can preserve the wrong thing for the wrong reason.
ADRs should exist for decisions like:
- database choice
- queueing model
- auth boundary
- monolith split
If those decisions are undocumented, stale, or contradictory, that is not administrative debt. It is evidence that the architecture may be held together by memory and habit. Decision intelligence, especially path-based decisions for a file or a no-arg health dashboard, is what turns “why does this look like this?” from a guess into a reviewable artifact. decision history and ADRs
A 30-minute diligence pass using only the four layers
The goal is not to be exhaustive. The goal is to make the next decision harder to fool.
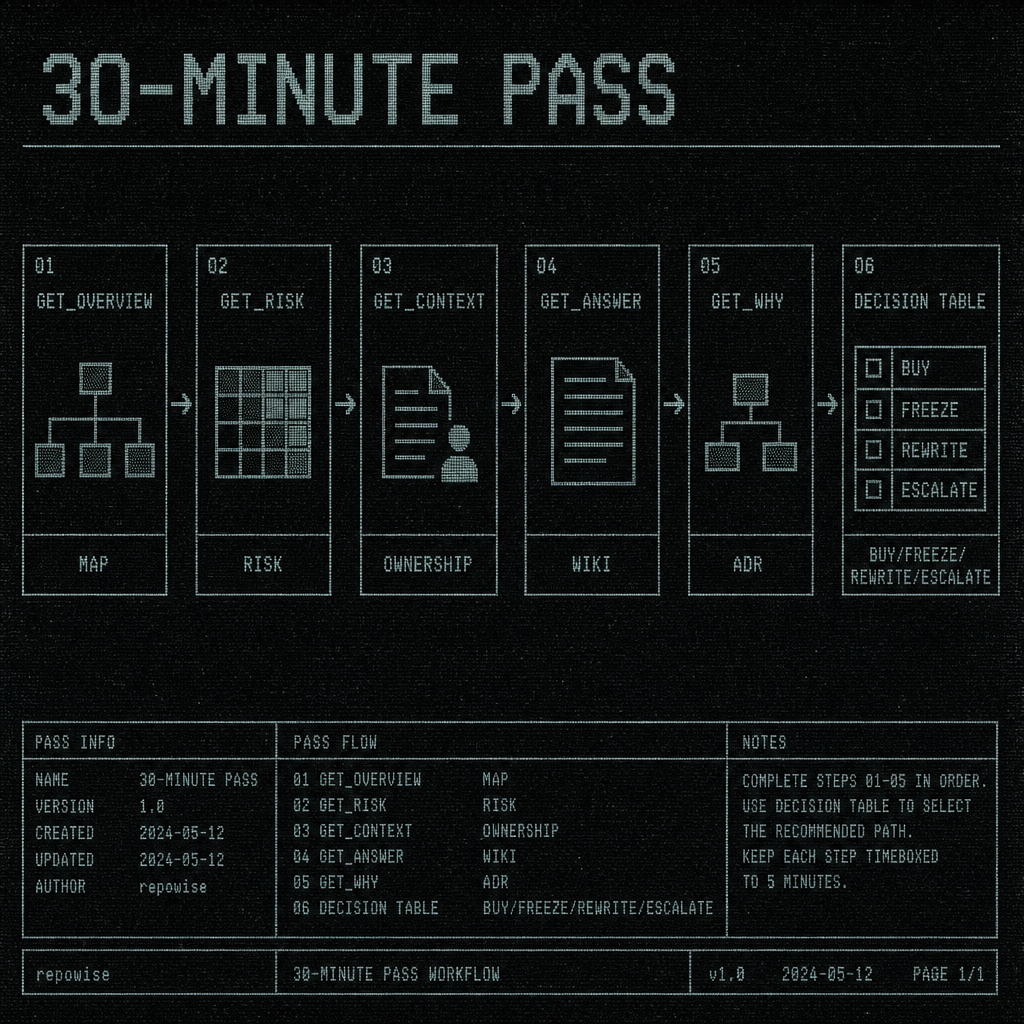
A workable sequence looks like this:
| step | tool or layer | question answered | output |
|---|---|---|---|
| 1 | get_overview | what is the shape of the repo? | module map, entry points, communities, git health |
| 2 | get_risk | what looks dangerous? | hotspots, dependents, co-change partners, blast radius, risk score |
| 3 | get_context | what is this file/module connected to? | docs, symbols, ownership, freshness, community context |
| 4 | get_answer | what does the wiki already know? | cited answer with confidence gate |
| 5 | get_why | why does this exist? | ADRs, decisions, staleness, missing decision gaps |
| 6 | get_context again | what changed around the suspicious module? | source, callers, callees, metrics, community |
That sequence is enough to answer the acquisition questions that matter: hidden coupling, ownership, stale docs, and architectural intent.
Here is the mini walkthrough as a diligence story.
A module shows up in get_overview as part of a central community. get_risk says it has many dependents and a high risk score. get_context shows it is owned by one person and sits near other critical paths. get_answer returns a wiki page with low freshness and medium confidence, which means the page is a lead, not truth. get_why finds no ADR for the queueing behavior that the module depends on, or worse, an ADR that conflicts with the code. That is enough to stop treating the module as an implementation detail.
The practical decision table is blunt on purpose:
- Safe to buy: graph shows manageable coupling, git shows distributed ownership, wiki is fresh enough, ADRs explain the shape.
- Safe to freeze: graph reveals risk but history is stable and intent is documented; you can pause changes without guessing.
- Safe to rewrite: graph and history both show concentrated risk, but ADRs are either missing or obsolete, so the current shape is not worth preserving.
- Needs deeper review: the signals disagree, especially when the wiki is stale but the graph and history are loud.
One thing surprised us when we started using the four layers together: the wiki was often most valuable when it was least trustworthy. That sounds backwards until you realize that stale docs still preserve the trail of what people thought they were doing. In acquisition work, that is often enough to find the next interview target or the next architectural fault line.
our token-efficiency benchmark
 30-MINUTE PASS
30-MINUTE PASS
FAQ
How do you audit legacy code before an acquisition?
Start with evidence from the repository itself. Read the graph to find blast radius, use git history to separate active risk from burial sites, check wiki freshness and confidence, then inspect ADRs for the reasons behind the architecture. The output should be a decision, not a report.
What should a pre-acquisition legacy code audit include?
At minimum: dependency graph analysis, git history analysis, documentation freshness scoring, and architectural decision records. If you are missing any of those, you are probably substituting opinion for evidence.
Can a dependency graph find hidden coupling in a monolith?
Yes. A tree-sitter dependency graph exposes callers, callees, entry points, SCCs, and execution flow, which is exactly where hidden coupling lives. Small files with high centrality are often the most dangerous ones.
How do you tell whether legacy documentation is stale enough to ignore?
Use freshness and confidence separately. If freshness is low, treat the page as historical evidence and a lead generator, not as truth. Cross-check it against graph and git signals before you rely on it.
What should architectural decision records tell you during an audit?
They should explain the tradeoffs behind the current shape: database choice, queueing model, auth boundary, monolith split, and similar decisions. Missing or contradictory ADRs are a risk signal because they make rewrite and freeze decisions easier to get wrong.


