One shared brain for the whole team.
Your team works on one system. Teams indexes each repo once and shares it with every member: one wiki, one graph, one credit pool, one org GitHub install, one PR bot, and a leader view across the whole portfolio.
N engineers on individual plans means N indexes of the same repo, N separate credit balances, and a PR bot that only sees the repos each person happened to connect.
The codebase is shared. The intelligence about it should be too. On solo plans every teammate pays to re-index the same code, burns a personal credit balance on questions a colleague already asked, and installs their own GitHub App. Nobody sees the whole portfolio, and nothing is governed. Teams collapses all of that into one shared layer.
Index once, everyone reads.
The foundation of the Teams tier: one shared copy of everything, with the roles and billing to run it as a team instead of a pile of personal accounts.
25 shared repos, indexed once
A repo the team adds is indexed one time, and every active member reads the same snapshot: the same wiki, graph, health scores, and decisions. No per-seat re-indexing of the same codebase, no drift between what two teammates see, and a repo limit that pools across the whole team instead of applying per seat.
- One index per repo, shared with every member
- 25 repos pooled across the team, not per seat
- Same snapshot for everyone: wiki, graph, health, decisions
- 6 concurrent index jobs so the queue keeps moving
A single GitHub App install for everyone
An admin installs the Repowise GitHub App once on the org. Every member's private-repo access flows from that single install, and so does the team PR bot. Nobody wires up personal tokens, and access ends when membership does.
- One admin install covers the whole org
- Private-repo access for every member from that install
- The team PR bot rides the same install
- No personal tokens to provision or revoke one by one
One credit pool, three roles
Every seat contributes $5/month of LLM credit into one team balance that the owner or an admin tops up centrally. Owner, admin, and member roles keep billing, membership, and repo management with the right people while every member gets the full product on shared repos.
- $5/seat/mo pooled into one team balance
- Centralized billing and top-ups, no expense reports
- Owner / admin / member roles
- $100/day team LLM cap so costs never run away
The Repowise PR Bot on every shared repo
The deterministic PR bot runs across all team repos from the single org install: one comment per pull request, only when there is something worth saying, with zero LLM calls in scoring. Every teammate sees the same risk read on the same PR, not just the person who installed a bot.
- Runs on all shared repos automatically
- One deterministic comment per PR, silence on green
- Zero LLM calls: same PR, same comment, every time
- Same engine as the team-lead risk tooling
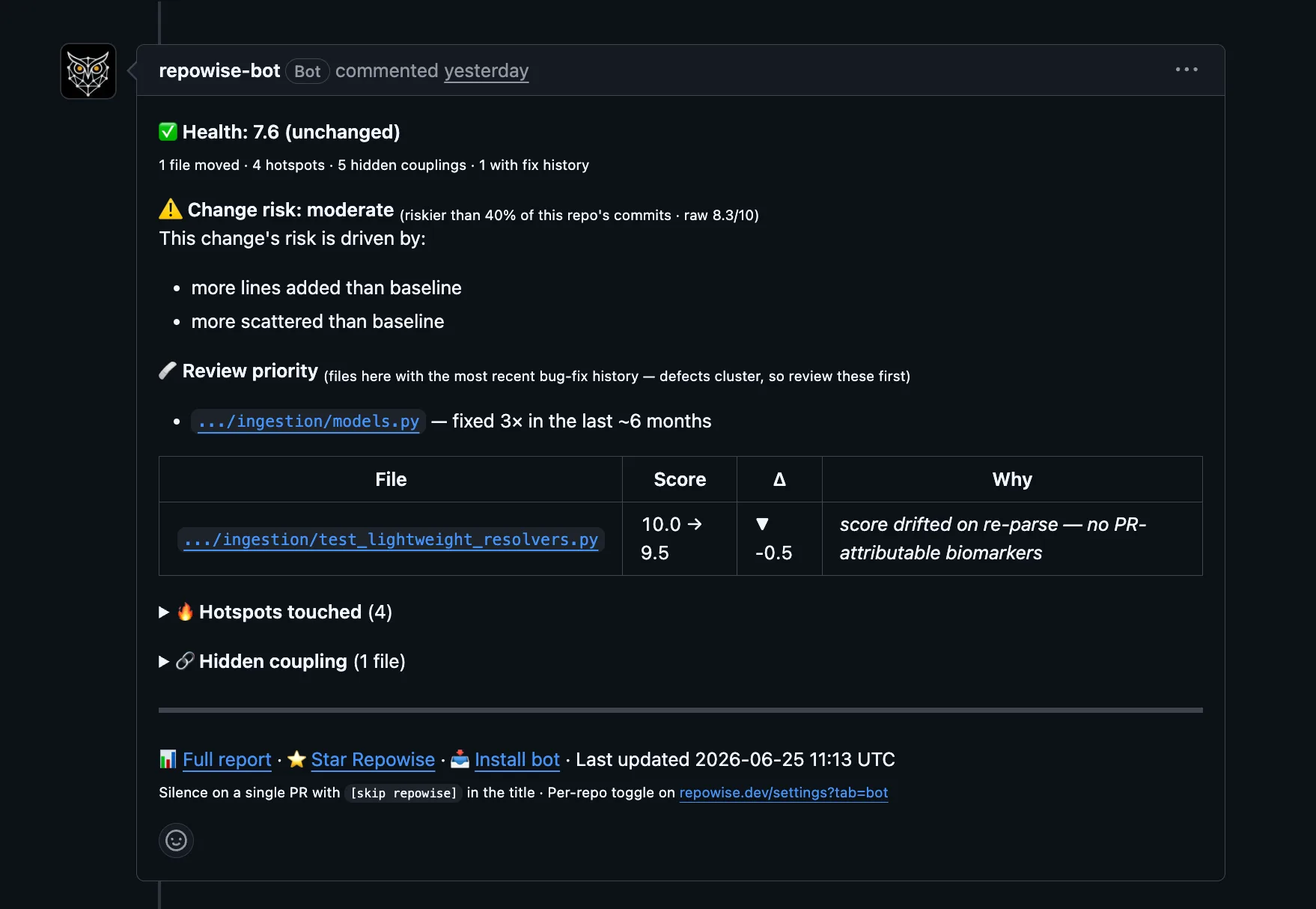
See the whole portfolio, not one repo at a time.
Teams adds the views a lead or manager needs and a solo plan never has: health across every repo, ownership risk, and a weekly pulse of what changed.
Every repo's health on one dashboard
Aggregate health scores, hotspots, and trends across every team repo in one view. Compare services, watch declining files surface before they bite, and decide where review effort and refactoring budget go with a defect-validated score rather than gut feel.
- Health scores and trends across all team repos
- Hotspots and declining files surfaced portfolio-wide
- Defect-validated scoring, deterministic and reproducible
- One view for where to invest review and refactoring effort
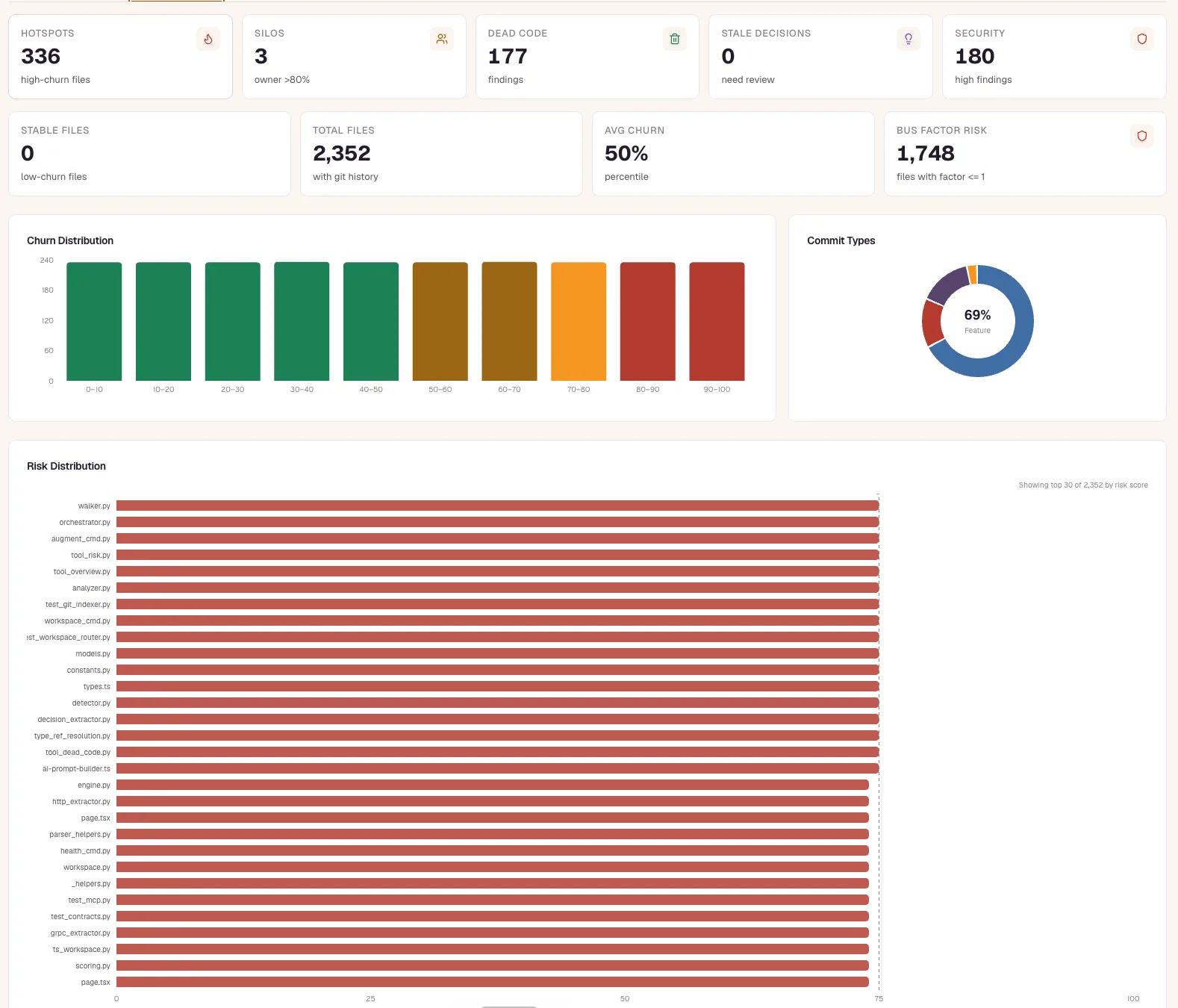
Key-person risk across every repo
Ownership concentration, knowledge silos, and bus-factor-of-one modules, computed from git history across the whole portfolio. See where tribal knowledge is dangerously concentrated while you can still spread it, not in the exit interview.
- Ownership percentage per file, module, and repo
- Bus-factor-of-one modules flagged across the portfolio
- Knowledge silos surfaced from history, no surveys
- Pairs with health to rank what to de-risk first
Drift detection with a weekly digest
Nightly checks across the portfolio catch hotspot drift, bus-factor risk, health decline, and decision staleness, rolled into a leader view of trends and recent alerts with a weekly digest. The things that go wrong slowly stop going unnoticed.
- Nightly drift detection across every team repo
- Hotspot drift, bus-factor risk, health decline, stale decisions
- Leader view of trends and recent alerts
- Weekly digest so the signal reaches you without a dashboard habit
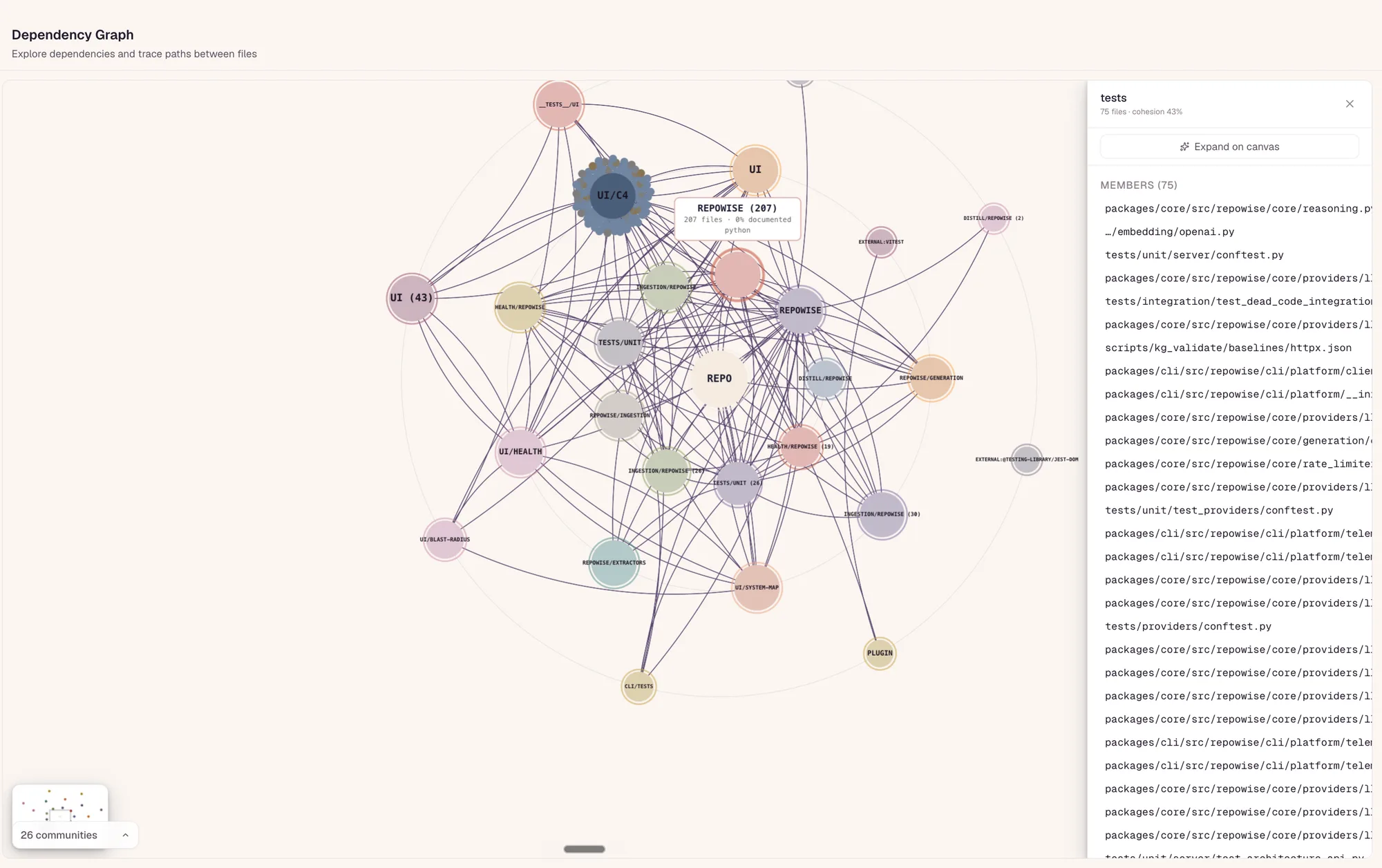
Your system is bigger than one repo.
Shared team workspaces stitch the repos into one system view every member can query.
Team-owned workspaces across repos
Group the services that make up your system into a shared workspace the whole team owns. The system map shows how the repos connect, contract matching links the API a frontend calls to the handler that serves it, and cross-repo co-change surfaces the services that keep shipping together. Every member queries the same workspace, including over MCP from their coding agent.
- System map across every repo in the workspace
- Contract matching from caller to handler across repos
- Cross-repo co-change: services that ship together, flagged
- Team-owned and shared, not one engineer's private view
Governed like team infrastructure, because it is.
Shared intelligence needs an answer to who saw what. Teams ships the governance layer alongside the features.
A security audit trail with export
Who viewed, exported, or changed security data, including AI-agent reads over MCP, recorded insert-only with actor, IP, and timestamp. Browsable in-product and exportable as JSON or CSV when someone asks for evidence.
- Insert-only trail with actor, IP, and timestamp
- Covers AI-agent reads over MCP, not just humans
- In-product view plus JSON/CSV export
Compliance reports and signed alerts
PCI-DSS and SOC 2 control-coverage reports derived from your live findings, with evidence drill-ins and export. HMAC-signed webhooks push security events and engineering signals into Slack, Microsoft Teams, or any HTTPS endpoint, with an opt-in audit-event stream for your SIEM.
- PCI-DSS / SOC 2 control-coverage reports with evidence
- Honest framing: a map of where an assessor will look, not an audit
- HMAC-signed security webhooks to Slack, Teams, or any endpoint
- Opt-in audit-event stream for your SIEM
Meet the tools your org already runs
Link architectural decisions to the Jira tickets that motivated them, and publish the generated wiki to a Confluence space on a weekly schedule, so the documentation lives where the rest of the org already looks.
- Decisions linked to the Jira tickets behind them
- Wiki published to Confluence on a weekly schedule
- No copy-paste documentation shuttling
Per seat, one pool, no surprises.
3-seat minimum. Every seat adds $5/month of LLM credit to the shared team pool, billed centrally by the owner or an admin.
- Everything in Pro, for every member
- 25 pooled repos, each indexed once and shared
- One org GitHub App install for the whole team
- Owner / admin / member roles
- Team PR bot across all shared repos
Five engineers on Pro pay for five indexes of the same repo. Five Teams seats pay for one.
A 5-seat team is $100/month with a $25/month shared credit pool, one snapshot of every repo, and one bot install, instead of five Pro accounts re-indexing the same codebase with five separate credit balances. And the portfolio, governance, and cross-repo layers only exist on Teams, at any price.
From one account to a shared brain in four steps.
Start a team
Pick Teams on the pricing page, name the team, and choose your seats. 3-seat minimum, $20/seat/month or $16/seat yearly.
Install once
An admin installs the Repowise GitHub App on the org. Every member's access and the PR bot flow from that single install.
Add your repos
Index up to 25 pooled repos once. Every member immediately reads the same wiki, graph, health, and decisions.
Invite the team
Members join with owner/admin/member roles, share the credit pool, and point their coding agents at the same MCP endpoint.
A pile of Pro accounts re-indexes the same code, splits the credits, and sees one repo at a time. Teams is the same engine run as shared infrastructure: one index per repo, one credit pool, one org install, and the portfolio, governance, and cross-repo layers that only make sense for a team.
Questions, answered
How does Teams billing work?
Teams is billed per seat with a 3-seat minimum: $20/seat/month, or $16/seat/month billed yearly. Every seat contributes $5/month of LLM credit into one shared team pool that the owner or an admin tops up centrally, so a 3-seat team starts with $15/month of pooled credit. You can add seats anytime from team settings, and you cannot have more active members than paid seats.
What does every member actually get?
Everything in Pro, applied to the shared team repos: the wiki, dependency graph, code health, git intelligence, codebase chat, semantic search, and MCP access for their coding agents. Private-repo access comes from the single org GitHub App install, so nobody wires up their own. Members draw on the shared credit pool for AI features on team repos, and anything they index personally still runs on their personal account.
How are repos shared across the team?
A repo the team adds is indexed once, and every active member reads the same snapshot: same wiki, same graph, same health scores, same decisions. There is no per-seat re-indexing of the same codebase and no drift between what two teammates see. The 25-repo limit pools across the whole team rather than applying per seat.
What is the difference between Pro and Teams?
Pro is built for one engineer: 5 repos, a personal credit balance, and a personal GitHub App install. Teams is built for an engineering org: 25 pooled repos indexed once and shared with everyone, per-seat billing with a shared credit pool, one org GitHub App install, owner/admin/member roles, and the team PR bot across all shared repos. Teams also adds the layers a solo plan never has: the portfolio health dashboard, ownership and bus-factor intelligence, engineering signals, shared cross-repo workspaces, the security audit trail, compliance reports, security webhooks, and Jira and Confluence integration.
Who can do what? How do roles work?
Teams has three roles. The owner controls billing, seats, and the team itself. Admins manage members, the org GitHub App install, team repos, and credit top-ups. Members use everything the team shares: repos, docs, chat, workspaces, and the credit pool. Sensitive actions land in the security audit trail, so who viewed, exported, or changed security data is always answerable.
What happens if we downgrade or cancel?
Cancellation takes effect at the end of the current billing period, and the team keeps working until then. After that, members fall back to their personal plan (Free or Pro), team-shared repos and the pooled credit balance stop being shared, and anything a member indexed personally stays on their personal account. Nothing you indexed personally is lost by leaving a team.
Last reviewed: July 2026
Free, Pro, Teams, and Enterprise, compared feature by feature.
Deterministic PR risk and the Repowise PR Bot, for the person running review.
AI provenance, code health, and ownership for the person accountable for it all.
Living documentation that stays in sync automatically, the lane Swimm vacated for agentic modernization.