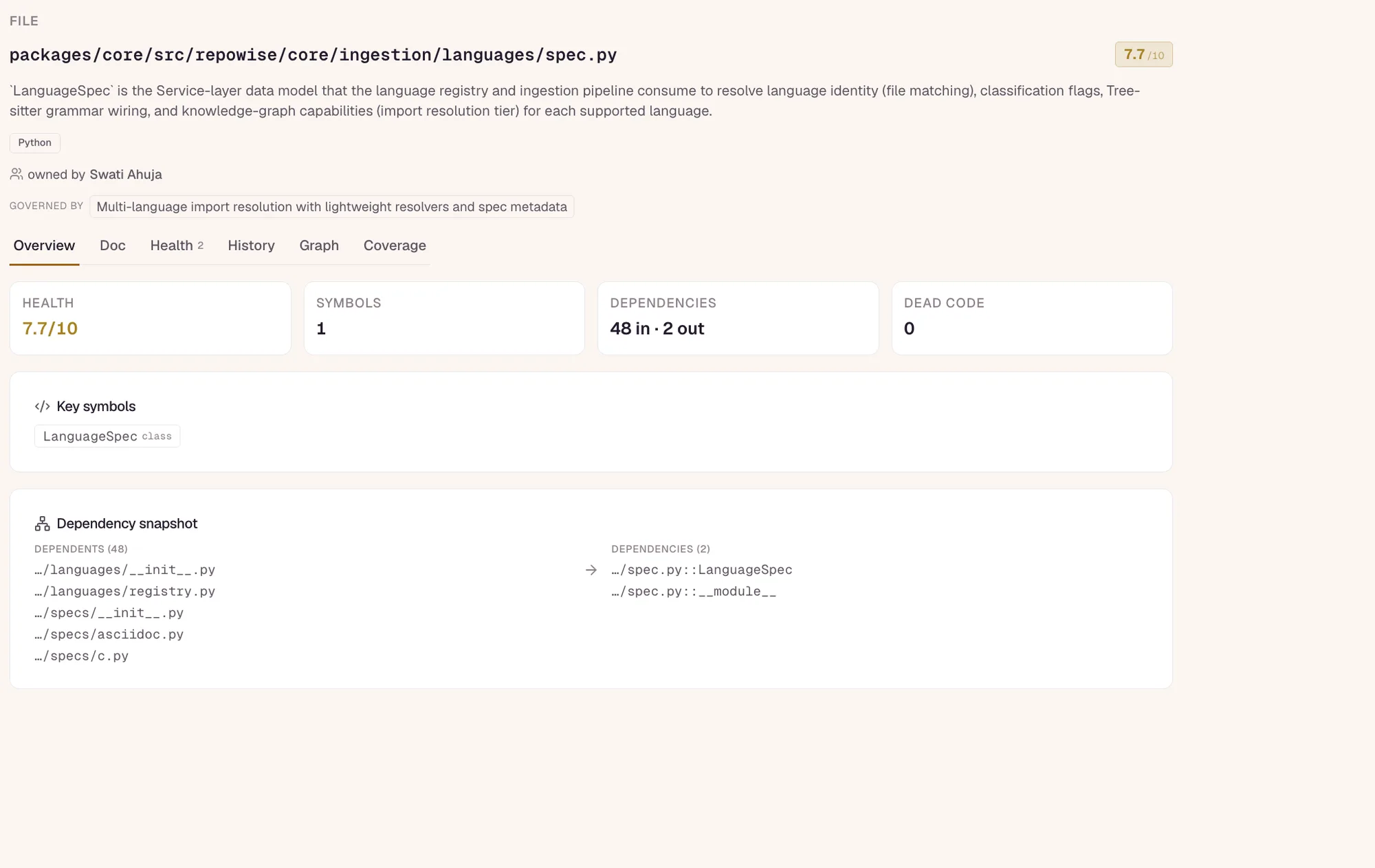
repowise indexes your repo once and exposes it to AI coding agents through nine task-shaped MCP tools, so the agent calls one tool and gets curated context — docs, ownership, history, risk — instead of grepping and re-reading files. On paired runs (same model, same harness, with versus without repowise), loading context took 2,391 tokens instead of 64,039 — 96% fewer, roughly 27x — at answer parity, plus 89% fewer file reads and 70% fewer tool calls. It is open source under AGPL-3.0, self-hostable, and works with Claude Code, Cursor, Cline, and Codex.
AI context over MCP is repowise serving your indexed codebase to AI agents through the Model Context Protocol. Instead of pasting files into a prompt, the agent calls a task-shaped tool — get_answer, get_context, get_risk — and receives curated, grounded context: documentation, ownership, git history, and risk in one round-trip, with a staleness envelope on every response.

Why does AI agent context matter?
Your agent burns thousands of tokens grepping, reading, and re-reading the same files to reconstruct context it should have been handed. Entity-by-entity tools force the model to do the retrieval itself: search, open, scroll, repeat.
The problem is fragmented context — the agent sees file fragments, never the whole picture. Each fragment costs tokens, and the model pays again on every retry when the first read missed.
- Token cost compounds: raw exploration of a single task can spend 64,039 tokens just loading context, before any reasoning.
- Retries multiply reads: a missed grep means another search, another open, another scroll.
- No enrichment: raw file reads carry no ownership, no history, no risk, no "why."
This is the wedge. repowise is reproducible — deterministic, the same input yields the same answer — and dual-audience, since the same index serves agents and humans, and private, since it is self-hostable with source processed transiently. It is not a public-repo wiki; it is a context layer you host yourself.
How does the repowise MCP server work?
One index, nine task-shaped tools, curated answers — not raw dumps. The pipeline is four steps.
| Step | What happens |
|---|---|
| Index | repowise parses the repo into a graph, reads git history, and builds the wiki. Code is processed transiently, never persisted. |
| Connect | Register the MCP endpoint in Claude Code, Cursor, Cline, Codex, or any MCP client. One URL, nine tools. |
| Call | The agent calls a task-shaped tool and gets a curated answer in one round-trip instead of grepping and re-reading. |
| Trust | Every response carries a _meta staleness envelope, so the agent knows when the index is current and when to verify. |
Task-shaped, not entity-shaped. Most MCP servers mirror data entities — one file, one symbol, one diff — which forces long sequential chains. repowise tools are shaped around the task the agent is doing. get_answer collapses search, read, and reason into one cited round-trip. get_context absorbs what would otherwise be five or six calls — docs, signatures, ownership, freshness, callers, metrics — into one.
The nine tools, by what only they answer
| Tool | What only this tool answers |
|---|---|
get_overview | One-time architecture orientation — the architecture map, key modules, entry points, and git health on an unfamiliar repo. |
get_answer | Synthesised Q&A with citations and a calibrated confidence; low confidence returns ranked best_guesses instead of a guess. |
get_context | A triage card for files, modules, or symbols — summary, signatures, ownership, freshness, the hotspot bit, governing decisions. |
get_symbol | Exact source bytes for one symbol with live-verified line bounds — no offset math, no 800-line file read. |
search_codebase | Concept search over the wiki when you know the concept but not the file — ranked pages with snippets and a search_method flag. |
get_risk | What history says about touching these files — hotspot score, dependents, co-change partners, owners, and a PR directive when you pass changed_files. |
get_why | Decision archaeology — why the code is shaped this way, falling back to git history when no ADRs exist. |
get_dead_code | A tiered cleanup plan — unreachable files, unused exports, and zombie packages by confidence tier, pure graph and SQL. |
get_health | Biomarkers and per-file scores across three signals (defect, maintainability, performance) — the same signals a merge-gate judges on. |
The staleness envelope. An index that lies is worse than no index. Every MCP response carries a _meta envelope with index_age_days, the indexed_commit, and a stale_warning that fires only when the index has actually diverged from HEAD. Silence means current, so the agent trusts a verified response without re-reading; the only re-read triggers are an approximate-bounds flag, a stale_warning, or low confidence.
How does it help you?
Fewer tokens, fewer retries, grounded answers, and provenance your editor never sees.
- Fewer tokens and retries: 96% less context to load and 70% fewer tool calls — the budget goes to reasoning, not file archaeology.
- Grounded answers:
get_answerreturns citations and a calibratedconfidence;highis content-grounded and citable without a verification read. - Provenance:
get_risksurfaces who owns the code, how risky it is to touch, and what changes with it.
The same index that feeds agents also answers who owns this, how risky is this change, and why is it shaped this way — and repowise keeps the generated CLAUDE.md and a managed AGENTS.md current so the orientation files never drift.
Walkthrough: connect your agent
Step 1 — Install and index. Run pip install repowise, then repowise init to build the graph, git, health, and wiki layers. Code is processed transiently and never persisted.
pip install repowise
repowise init # index the repo + register the MCP server
Step 2 — Register the MCP endpoint. repowise init writes .mcp.json and auto-registers the server for Claude Code. For Cursor, Cline, or Codex, drop the same mcpServers block pointing at repowise mcp <project>.
Step 3 — Call a task-shaped tool. Ask the agent a "how does X work" question and it calls get_answer or get_context, getting a curated answer in one round-trip instead of grepping and re-reading.
Step 4 — Trust the staleness envelope. Every response carries a _meta envelope with index_age_days, the indexed_commit, and a stale_warning that fires only when the index has diverged from HEAD. Silence means current.
Proof: the paired token benchmark
Each stat below is reproducible on your own repo, and the headline is a paired, same-model-same-harness comparison — not an estimate.
| Metric | Result | Method |
|---|---|---|
| Context tokens to load | 2,391 vs 64,039 — 96% fewer (~27x) | Paired runs, same model + harness, with vs without repowise |
| File reads | 89% fewer | Across benchmarks, at answer parity |
| Tool calls | 70% fewer | flask48 and sklearn48 benchmark suites |
| Task-shaped MCP tools | 9 | One endpoint, every MCP client calls the same set |
| Defect-validated health score | ROC AUC 0.74 | Surfaced to agents via get_health, calibrated on a real defect corpus |
| License and deployment | AGPL-3.0, pip install, self-host | Code processed transiently, never persisted |
The headline is the paired benchmark: 96% fewer tokens (2,391 vs 64,039) is a hard, paired, same-model-same-harness context-token comparison, with answer quality held at parity.
How each role uses this feature
Give your coding agent a queryable model of the repo: get_context returns a triage card and get_symbol fetches one body, so the agent stops re-reading whole files — 96% fewer context tokens at answer parity.
Run the same index inside your firewall and query the whole estate from one federated MCP endpoint, with source processed transiently and never persisted.