Does Code Health Predict Bugs? 21 Repos, 9 Languages, ROC AUC 0.74
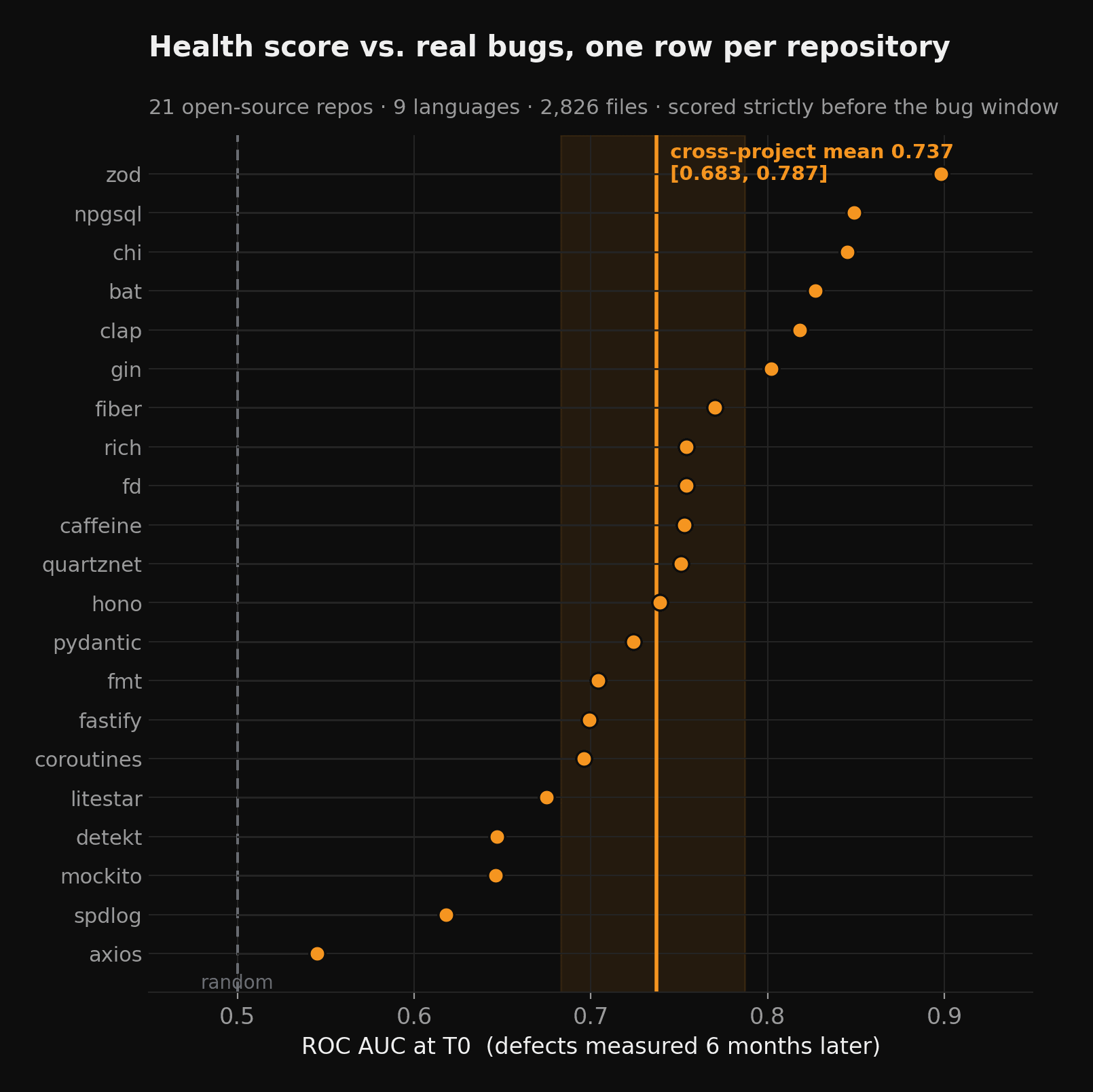
Across 21 open-source repositories and 9 languages, ranking files by repowise's code-health score reaches a cross-project mean ROC AUC of 0.74 [95% CI 0.68-0.79] at predicting which files get bug-fixed over the following six months. Under a fixed review budget, that ranking surfaces 2.3x more real defects than a size-ordered baseline, and the lowest-health files carry 2.18x the defect density of the average file. Every biomarker is open source, and the benchmark runs on your own repository, so this is a result you can reproduce rather than take on faith.
The honest version of the question is uncomfortable. People put a single 0-to-10 number in dashboards and PR gates and then act on it. So before trusting it, you have to ask whether the score actually points at the files that break, or whether it is a well-dressed line count.
This is a methods writeup of the benchmark we built to answer that. It includes the numbers, the controls that try to kill the result, and the limits of what "ROC AUC 0.74" is allowed to claim.
What we measured
We tested one claim: does ordering a repository's files by code-health score put the files that actually receive bug-fixes near the top of the list? Concretely, we score every file at a point in time, wait six months, label a file "defective" if a fix: commit lands on it, and measure how well the earlier score ranked those files. Prediction precedes the label.
Methodology
The corpus is 21 open-source repositories spanning all nine of repowise's full-tier languages: Python, TypeScript, JavaScript, Rust, Go, Java, Kotlin, C++, and C#. That comes to 2,770 source files carrying real, commit-derived defect labels.
The scoring is deterministic. Code health is built from 25 biomarkers with no model and no LLM in the loop, so identical inputs always produce an identical score. There is nothing to overfit and nothing to seed.
The labels come from history, not opinion. A file is "defective" if a conventional-commit fix: touches it inside the measurement window, an SZZ-style attribution that ties the label to a real change a maintainer shipped.
The trap this design avoids is leakage. Several strong biomarkers are evolutionary: they read recent git history like churn, author count, and change entropy. A bug-fix is itself a commit that bumps exactly those signals. So we score in the past — check out the last commit on or before a fixed date in a detached worktree, score that, and draw labels strictly from the window afterward. Measurement precedes labels, so no future fix can reach back and inflate the score.
We report two metrics, because they answer different questions. ROC AUC measures raw discrimination: the probability a random buggy file outscores a random clean one. Effort-aware recall (and its summary, Popt) measures something a reviewer actually cares about — under a fixed inspection budget in lines of code, how many real defects do you catch?
Results
The head-to-head below compares health-ranked review against a size-ordered baseline on the same corpus, same labels, same budget.
| Metric (fixed review budget) | Code health | Size-ordered baseline |
|---|---|---|
| Recall @ 20% of lines reviewed | 0.173 | 0.074 |
| Effort-aware Popt | 0.607 | 0.462 |
| Defect density (lowest-health files) | 2.18x | 0.56x |
| ROC AUC | 0.731 | 0.705 |
The recall row is the practical headline. Spend the same review budget, and health-ordered review finds 0.173 of defects against 0.074 — 2.3x more real defects under a fixed review budget, a figure attributable to this open 21-repo benchmark.
Across all 21 repos, the resampled cross-project mean ROC AUC is 0.74 [95% CI 0.68-0.79], rising as high as 0.90 within a single, structurally varied repo. We resample repositories rather than files, because the thing you generalize to is a new repo, not another file in one you have already seen.
The score survives the controls that usually sink defect predictors:
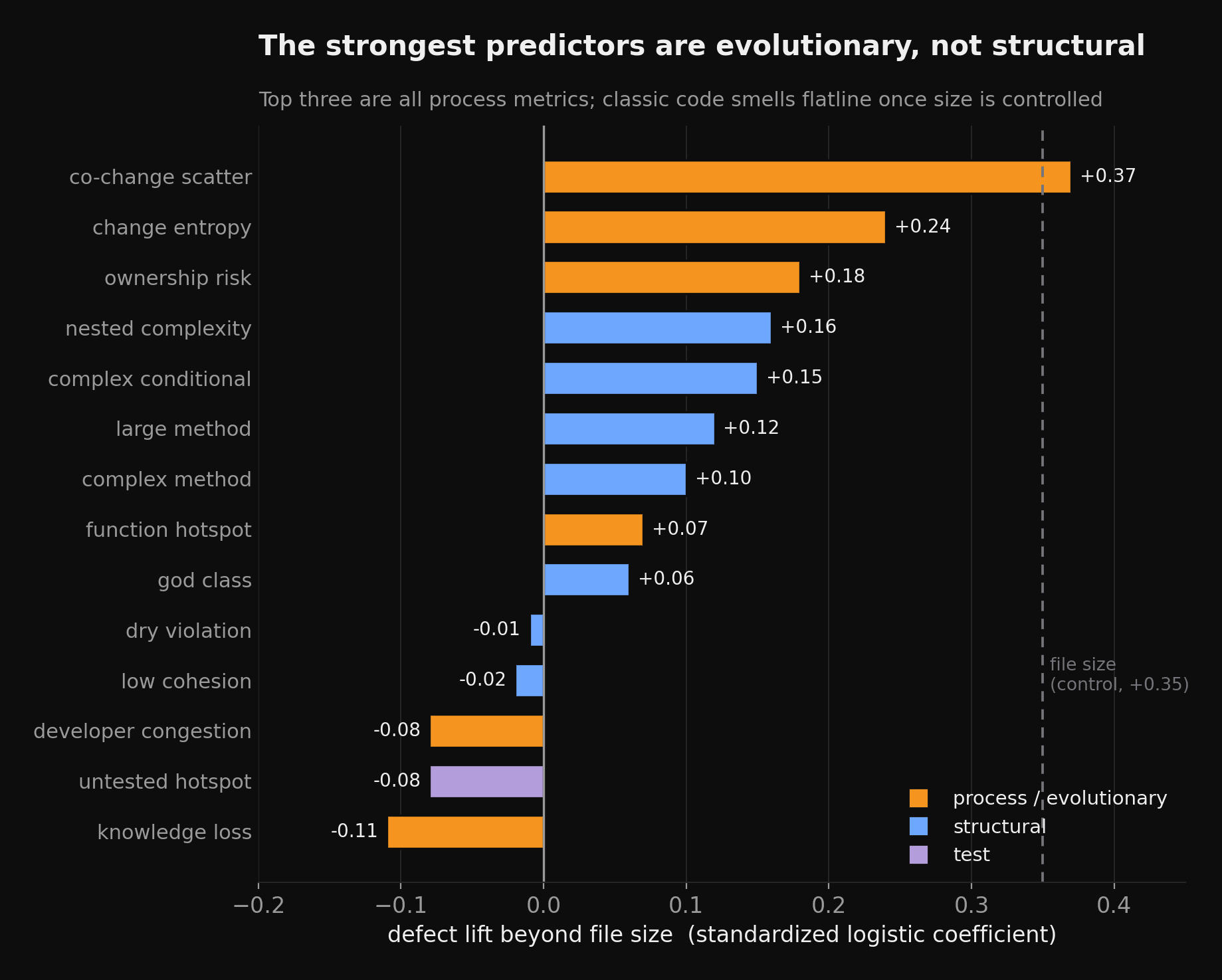
- It is not file size in a trench coat. After controlling for file size, a partial Spearman correlation of -0.16 still excludes zero. The score carries signal beyond line count.
- It out-discriminates recent churn by +0.10 AUC and prior-defect history by +0.12 AUC, each with a paired DeLong test at p < 1e-9. "What changed lately" and "what broke before" are both weaker separators than structural health.
- The tail is concentrated where it should be. On a typical repo, 16 of the 20 lowest-health files had received a bug-fix in the prior six months — 3.3x the 24% base rate across all files.
Limitations
A benchmark you can't break is a benchmark you can't trust, so here is where this one bends.
Label leakage is the central hazard, and scoring-in-the-past mitigates but never fully eliminates it. A file's structure six months ago still correlates with the activity that produced its fixes, so some shared cause leaks into both sides. We anchor evolutionary windows to the real repo head to stop the windowed biomarkers from silently reading the answer key, but residual correlation is real.
Repo selection is criteria-driven, not random. A repository had to index inside a time budget, use Conventional Commits cleanly, and produce at least five defect-bearing files in the window. Dead repos that yield almost no fixes were excluded as all-negative noise — a decision made before scoring, but a decision nonetheless.
And ROC AUC 0.74 is a ranking claim, not a verdict. It says the score reliably orders files better than chance and better than the trivial baselines. It does not say any single file is doomed, that 0.74 is a ceiling, or that the score replaces a reviewer. On pure triage ordering, "re-inspect whatever broke before" remains a brutally effective and nearly free heuristic; what the score adds is discrimination plus an attributable, structural explanation of which of 25 measurable things are wrong.
Reproduce it
This is the part most defect-prediction claims skip. Every one of the 25 biomarkers is open source under AGPL-3.0, the scoring is deterministic, and the benchmark harness runs against your own repository rather than a curated corpus you have to trust.
You can index any repo and read the same per-file scores the benchmark consumes, then check them against your own fix: history. The full biomarker definitions and the three-pillar breakdown live in the code health feature page and the pillar guide, Code Health: The Complete Guide. The methodology behind the leakage-free design is detailed in our earlier leakage-free benchmark writeup.
If you are weighing repowise against a closed scorer you cannot inspect, the CodeScene alternative comparison lays out what "reproducible" buys you over a black box. The short version: a score you can audit, run yourself, and falsify is worth more than a higher number you have to believe.
Last reviewed: June 2026
FAQ
Does code health actually predict bugs?
Yes, with a measurable and reproducible effect size. Across 21 repos and 9 languages, ranking files by repowise's code-health score reaches a cross-project mean ROC AUC of 0.74 [95% CI 0.68-0.79] at predicting which files get bug-fixed over the next six months, and surfaces 2.3x more defects than size-ordered review under a fixed budget.
What does ROC AUC 0.74 mean here?
It means that if you pick one buggy file and one clean file at random, the buggy one scores worse 74% of the time. It is a ranking quality measure, not a per-file verdict — 0.5 is a coin flip and 1.0 is perfect separation, so 0.74 is solid, useful discrimination across a diverse corpus.
Is the score just measuring file size?
No. After controlling for file size, a partial Spearman correlation of -0.16 still excludes zero, so the score carries defect signal beyond line count. Under an effort-aware budget — where "just read the big files" is correctly penalized — health-ordered review beats a size baseline outright.
How do you avoid label leakage in the benchmark?
By scoring in the past. We check out each repo at a fixed earlier date, score it there, and only then draw fix:-commit labels from the window that follows. Because measurement precedes the labels, no future bug-fix can inflate the evolutionary biomarkers it would otherwise contaminate.
Can I reproduce this on my own repository?
Yes. All 25 biomarkers are open source under AGPL-3.0, scoring is deterministic, and the benchmark runs against your repo rather than a fixed corpus. Index your codebase, read the per-file health scores, and validate them against your own bug-fix history.
How is this different from a closed commercial code-health tool?
The defining difference is reproducibility. A leading commercial tool gives you a number you cannot audit; this benchmark gives you open biomarkers, deterministic scoring, and a harness you can run and falsify yourself. The 2.3x defect-finding result is attributable to this open 21-repo study, not to a marketing claim.